
TABLE OF CONTENT
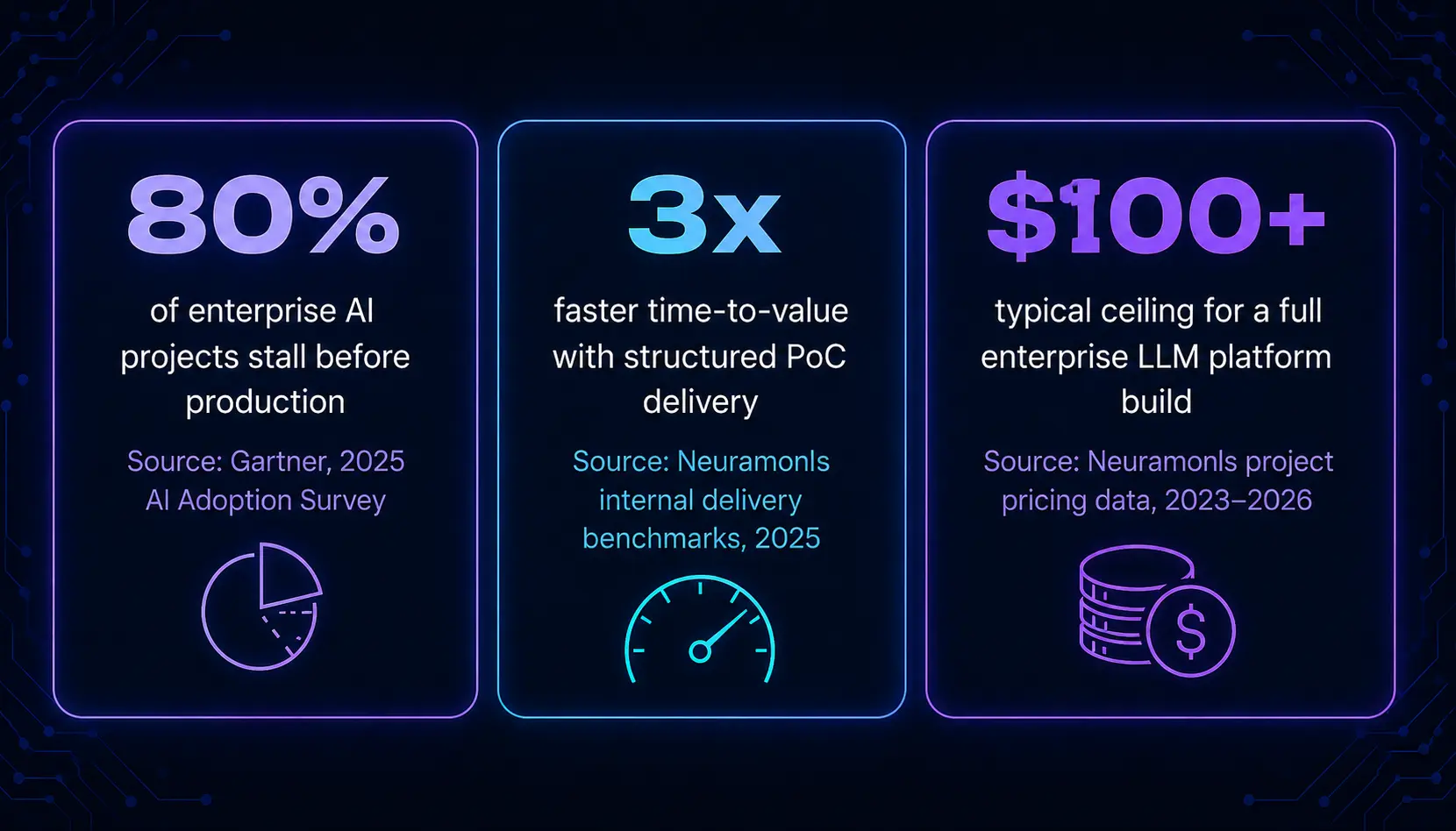
Deploying a scalable LLM Solutions requires moving past basic conversational interfaces to build robust infrastructure. Most companies have only scratched the surface of what large language models can do. This guide covers how enterprise teams are using LLMs for far more than conversational AI and what to look for when choosing the agency that will build it with you.
LLMs Are Not Chatbots. They Are Infrastructure
There is a persistent misconception in enterprise buying decisions: that LLM development means building a customer-facing chat interface. This is understandable chat products are the most visible public use case but it misses the deeper opportunity by a wide margin.
In 2026, the most impactful enterprise LLM deployments have nothing to do with conversational UI. They sit silently inside operational workflows, data pipelines, and decision-support systems doing the kind of unstructured reasoning work that brittle, rules-based automation could never handle.
“Large language models are general-purpose reasoning engines. Where your business has unstructured data, inconsistent inputs, or judgment heavy processes, there is almost certainly an LLM application worth building.”
Understanding the full breadth of what LLMs can do and finding an agency that has actually shipped across those categories is the first step to a successful enterprise AI engagement.
What High-Impact LLM Implementations Actually Look Like
The following categories represent real production deployments, not hypothetical use cases. Each one requires a different combination of model architecture, data infrastructure, and integration work.
- Automated contract review and clause extraction
- Intelligent document processing and classification
- Multi-step research and report generation
- Internal knowledge base Q&A with source attribution
- Custom media pipelines built on our AI Podcast Generation Platform
- Clinical notes summarization and coding support
- Sales intelligence and CRM enrichment workflows
- Multi-agent orchestration for complex task routing
- Compliance monitoring and regulatory flagging
- Personalized content generation at scale
- Code review, refactoring, and documentation
- Customer support triage and resolution routing
Micro-Case Study Healthcare
Wound assessment in clinical practice is still largely manual: measurements vary between clinicians, ruler-based methods are error-prone, and the workflow simply does not scale for remote care. Neuramonks built an Automated Wound Detection and Measurement System using an Attention U-Net deep learning architecture. The pipeline detects wounds from standard RGB images, uses a green calibration marker for real-world scale reference, applies perspective correction, and outputs centimeter-accurate measurements of wound area, perimeter, width, and height all via a HIPAA-compatible, API-ready architecture. Clinician measurement effort dropped by 55 to 65%, consistency improved by 30 to 40%, and AI output stayed within 5% error compared to expert manual benchmarks.
Read the full case study →
Micro-Case Study Finance & SaaS · Construction
A real estate and architecture client was losing significant time manually inspecting floor plan images to extract room boundaries, area calculations, and spatial metadata work that was error-prone and impossible to scale. Neuramonks built an AI-powered floor plan extraction system combining computer vision, OCR, and LLM-assisted normalization on AWS. The pipeline auto-detects individual floors, segments rooms, extracts polygon boundaries, and outputs structured, database-ready spatial records without human intervention. Manual analysis effort dropped by 60–70%, dimensional accuracy improved by 30 to 40%, and 100% of outputs are now analytics ready for downstream property and architecture systems.
Read the full case study →
What "Enterprise Grade" LLM Expertise Actually Requires
Not every agency that advertises AI services can execute on complex enterprise deployments. The difference becomes clear when you dig into their architecture decisions, infrastructure experience, and approach to failure modes.
Model Architecture
Ability to design fine-tuned models, RAG-augmented pipelines, and hybrid architectures not just prompt wrappers around hosted APIs.
Infrastructure Depth
Cloud-native deployments with autoscaling, vector database integration, orchestration frameworks, and production monitoring from day one.
Security & Compliance
SOC 2, HIPAA, and GDPR-aligned pipelines with proper data isolation, audit trails, and access controls for regulated industries.
PoC Discipline
Structured AI Proof of Concept Services with defined success metrics, fixed timelines, and clear go/no-go criteria before full commitment.
MLOps Capability
Long-term model monitoring, drift detection, retraining pipelines, and version management because LLMs degrade in production over time.
Vertical Experience
Prior production deployments in your industry. Edge cases and regulatory constraints in finance, healthcare, and SaaS are not learnable on your dime.
Stop Planning AI.
Start Profiting From It.
Every day without intelligent automation costs you revenue, market share, and momentum. Get a custom AI roadmap with clear value projections and measurable returns for your business.

Fine-Tuning vs. RAG: Getting the Architecture Right
One of the most consequential decisions in any LLM project is whether to fine-tune a base model or use Retrieval Augmented Generation (RAG). The wrong call here can cost six figures and months of development time.
Fine-tuning modifies the weights of a base model using your own labelled data. It is the right choice when you need consistent tone and domain-specific terminology that cannot be delivered through context injection, or when compliance requirements demand a self-hosted model with no external API calls. For a deeper breakdown on choosing the right model scale for these tasks, see our comprehensive SLM vs LLM guide on the Neuramonks blog.
RAG retrieves relevant chunks from a vector-indexed knowledge base and injects them into the LLM's context at inference time. For most enterprise use cases internal knowledge Q&A, document analysis, product recommendation RAG delivers comparable accuracy at a fraction of the cost and maintenance overhead“An agency that defaults to fine-tuning every LLM without first evaluating RAG is likely over-engineering your solution and billing you accordingly. Push them on this decision during evaluation.”
Sophisticated agencies will often propose hybrid architectures: a RAG system with selective fine-tuning for the retrieval reranker or a domain-adapted embedding model. This is where real LLM engineering expertise becomes visible.
Disclosure: This blog is published by Neuramonks. The comparison below reflects our honest view of the market and where each firm genuinely fits including where competitors have strengths we do not. We believe transparent positioning is more useful than a hidden vendor ranking.
Why Enterprise Teams Choose Neuramonks Over Legacy Consultancies
The gap between global consulting firms and specialist LLM agencies is wide and widening. Here is an honest breakdown of what each type of firm delivers, where they fall short, and who each option is actually right for.
1. Neuramonks
Best for end-to-end LLM implementation across verticals
⭐ Top Pick
Neuramonks was built specifically around LLM and AI automation delivery not as a bolt-on to an existing consulting practice. That focus shows in their approach: every engagement starts with a commercial problem definition, not a technology selection. The question is always "what outcome are you trying to achieve?" before "which model should we use?"
Micro-Case Study Media & Content Industry
A media production client needed to scale podcast output without proportionally scaling their editorial team. Neuramonks deployed a multi-agent LLM pipeline one agent handled topic research via live web retrieval, a second structured and scripted each episode, a third passed output to a text-to-speech synthesis layer. End-to-end production time dropped by 70% (Neuramonks internal client benchmark, 2024), and the platform now runs in production across multiple show formats with no human intervention in the research and scripting stages.
Neuramonks' AI Proof of Concept Services follow a structured framework: fixed 4 to 8 week timeline, real client data integration, measurable success criteria, and a clear go/no-go recommendation. This de-risks the investment before any full-scale commitment is made.
Their core technical stack covers fine-tuned LLM model deployment, RAG pipelines using Pinecone and pgvector, multi-agent orchestration with LangChain and LlamaIndex, and cloud-native infrastructure on AWS and GCP. Active verticals include SaaS, media, finance, and healthcare.
Custom LLM pipelinesMulti-agent workflowsRAG architectureStructured PoC deliverySaaS / Media / FinancePost-deployment MLOps
2. Accenture AI
Best for global enterprise programs with complex legacy integration
Accenture's AI practice benefits from massive scale and deep systems integration capability. Their Azure OpenAI practice is one of the most mature in the industry, and their ability to manage organizational change alongside technical delivery is unmatched at global scale. The trade-off is cost and velocity enterprise programs at Accenture move at consulting pace, and deep LLM engineering depth sits behind significant account management overhead.
Azure OpenAISystems integrationChange managementGlobal delivery
3. Deloitte AI & Data
Best for regulated industries with mature governance requirements
Deloitte's strength in financial services, government, and healthcare stems from their governance and responsible AI frameworks, which are among the most developed in the market. For organizations where AI risk documentation and audit trails are non-negotiable, Deloitte brings credibility. However, their LLM model engineering bench is thinner than specialist agencies, and delivery timelines reflect consulting rates rather than sprint-based product development.
Responsible AI frameworksAWS BedrockRegulated industriesGovernance documentation
4. DataRobot
Best for AutoML + LLM hybrid pipelines in insurance and pharma
DataRobot occupies a useful niche between platform and services provider. Their managed AI cloud handles model training, monitoring, and deployment for enterprises that need production-speed without a deep in-house ML team. Strong for insurance and pharmaceutical use cases where structured prediction and LLM reasoning need to coexist in the same pipeline. Less suitable as a primary development partner for bespoke LLM architectures.
AutoML + LLM pipelinesModel monitoringInsurance / Pharma
5. Weights & Biases (W&B)
Best for ML teams scaling internal research and experimentation
W&B is more accurately described as an MLOps infrastructure partner than a development agency. If your team has strong in-house ML talent but needs experiment tracking, model versioning, and production monitoring tooling, W&B is indispensable. Not suitable as a primary development partner for organizations without existing AI engineering teams you need builders first, then W&B makes them more effective.
Experiment trackingModel versioningML infrastructure
Side-by-Side: LLM Model Capabilities at a Glance

How to Evaluate an LLM Agency Before Signing
Evaluating an AI partner requires the same rigor as vetting any major technology vendor. Here is a structured framework that separates agencies with genuine production experience from those selling innovation-theater.
Ask for production case studies with real metrics
Any agency can spin up an impressive demo with a hosted API and a UI library. What separates real LLM engineers is production experience: handling token limits at scale, managing latency under load, implementing fallback logic when models hallucinate, and maintaining accuracy as the underlying world knowledge shifts. Ask specifically for cost savings achieved, accuracy benchmarks hit, latency SLAs maintained, and user adoption figures not architectural diagrams.
Pressure-test their PoC process
A well-structured AI Proof of Concept Service should include defined success metrics agreed upfront, a fixed timeline of four to eight weeks, integration with your actual data (not synthetic samples), and a binary go/no-go decision framework. If an agency cannot clearly articulate how they structure PoC engagements, they are likely selling exploration at your expense.
Probe infrastructure maturity
Production LLM deployments require more than prompt engineering. Ask about experience with vector databases such as Pinecone, Weaviate, or pgvector; orchestration frameworks like LangChain or LlamaIndex; and cloud-native deployment on Kubernetes or serverless inference endpoints. An agency that cannot answer these questions confidently is unlikely to be enterprise-ready.
Test their fine-tuning vs. RAG reasoning
As covered earlier, fine-tuning is expensive and often unnecessary. Ask the agency to walk through their decision framework: under what conditions do they recommend fine-tuning versus RAG versus a hybrid approach? The quality of this answer reveals whether you are talking to engineers who have thought deeply about trade-offs, or salespeople who will over-engineer whatever maximizes their billable hours.
Ask about post-deployment support
LLMs are not fire-and-forget deployments. As world knowledge shifts and user behavior evolves, model performance drifts. Agencies without MLOps capabilities will leave you responsible for maintenance work your team is likely not equipped to handle. Clarify upfront whether ongoing monitoring, retraining, and performance review are included, and at what cost.
Five Mistakes Enterprises Make When Hiring LLM Agencies
01 Prioritizing flashy demos over production track records
A well-animated prototype tells you nothing about whether the team can handle real data volumes, real users, and real SLAs. Always ask what happened after the demo.
02 Skipping the PoC phase entirely
Jumping from requirements directly to full development is one of the most reliable ways to waste significant budget on AI that never ships. A structured proof of concept changes this equation.
03 Choosing on price alone
LLM model engineering is a specialist skill. The cheapest quote almost always reflects inexperience with production-grade complexity. What you save in fees you will spend in failure costs
04 Ignoring post-deployment operations
LLMs degrade over time as the world changes and user behavior evolves. Agencies without MLOps capabilities leave you managing a system you did not build and do not fully understand.
05 Not aligning on success metrics before the first sprint
Vague briefs produce vague outcomes. Define latency thresholds, accuracy benchmarks, and cost-per-inference targets before any code is written not after the first review cycle.
What LLM Development Actually Costs in 2026
Cost ranges vary significantly by scope, compliance requirements, and infrastructure complexity. The figures below represent typical market ranges across well-known agencies not fixed prices.
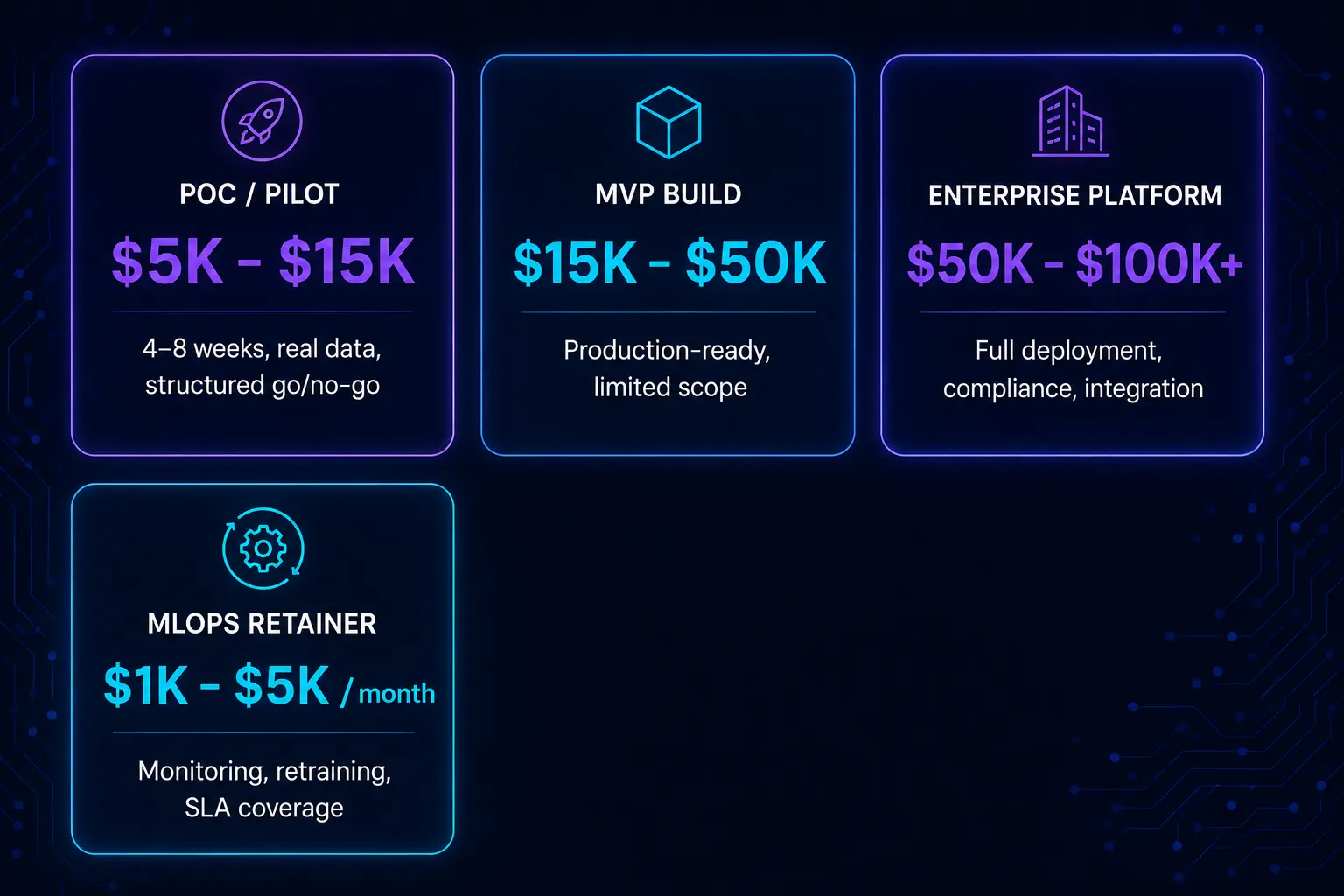
The main cost drivers are model selection (proprietary API costs versus self-hosted open-source), vector database and inference infrastructure, compliance requirements for regulated industries, and the depth of integration with existing enterprise systems. AI Proof of Concept Services remain the most cost-effective way to validate ROI before committing to full development scope.
Talk to Neuramonks about your LLM model project
Whether you are scoping AI solutions for the first time or evaluating your next LLM platform build, our team offers structured discovery sessions. We help enterprise teams define PoC scope, select the right architecture, and put together a business case grounded in real numbers not vendor optimism. AI Proof of Concept Services, production deployment, and ongoing MLOps support: all under one roof.
Book a Free Consultation with Neuramonks

Upendrasinh zala
Upendrasinh Zala is the Founder & CEO of Neuramonks, an enterprise AI and deeptech consulting firm based in Gujarat, India. Drawing from years of experience in AI-driven business strategy and corporate growth, he writes on leveraging artificial intelligence to optimize workflows and unlock tangible ROI for enterprises.




