TABLE OF CONTENT
Quick Answer
RAG is failing because it treats knowledge as proximity, not reasoning. Chunks lose context. Multi-hop questions break. Hallucinations persist. Five proven alternatives are delivering results: Graph-Enhanced RAG for relational knowledge, Agentic RAG for iterative reasoning, Hierarchical Chunking for context preservation, Hybrid Retrieval + Re-ranking for precision, and Talk to Data for real-time computation. Choose based on your query complexity and knowledge structure. Start with our free RAG Audit to diagnose where your system fails.
The Quiet Collapse of a Once-Great Idea
Not long ago, Retrieval-Augmented Generation felt like the answer to every enterprise AI prayer. Feed your LLM a knowledge base, pull relevant chunks at query time, and suddenly your language model knew things it was never trained on. Clean. Elegant. Deployable in a weekend.
Then production happened.
Queries returned wrong chunks. Reasoning broke when context spread across multiple documents. Hallucinations persisted. Latency spiked. Costs ballooned. Teams hired consultants, rewrote pipelines, and still found themselves debugging the same Standard RAG failure modes every sprint cycle. The architecture that once felt cutting-edge now feels like duct tape on a structural crack.
This is not a niche developer complaint. It is a widespread reckoning across every industry trying to build reliable, context-aware AI systems. And the most sophisticated teams have stopped patching Standard RAG. They have started replacing it.
The Real Cost of Waiting
Every quarter your enterprise stays on broken RAG, your competitors advance. They're deploying next-gen architectures. They're reducing hallucinations. They're scaling to handle multi-hop reasoning. They're turning questions into measurable business outcomes.
What does that cost you in revenue?
- Delayed decision-making from unreliable outputs
- Engineer hours spent debugging retrieval failures
- Eroded trust in AI systems—users stop using them
- Competitors making faster, smarter decisions with better data
The architecture gap widens faster than most realize. Organizations that act now—not in 6 months—gain a compounding advantage.
Stop Planning AI.
Start Profiting From It.
Every day without intelligent automation costs you revenue, market share, and momentum. Get a custom AI roadmap with clear value projections and measurable returns for your business.

Why Standard RAG Was Never Truly Built for Production
Standard RAG operates on a deceptively simple premise: split documents into chunks, embed those chunks as vectors, retrieve the top-K most similar chunks at query time, and pass them as context to a language model. It works remarkably well in demos.
In production, the cracks appear fast:
The Three Failure Modes That Kill RAG:
- Lost Context — Chunking destroys narrative flow and relational context. A table referencing figures from previous pages? Lost. A legal clause modifying an earlier section? Invisible to the retriever.
- No Multi-Hop Reasoning — A question requiring synthesis from three separate sources comes back as three unrelated excerpts, not an integrated answer.
- Proximity ≠ Relevance — Enterprise knowledge is rarely a vector proximity problem. It's a reasoning problem—understanding dependencies, hierarchies, timelines, and logical chains that flat vector search cannot model.
The core problem is architectural. Standard RAG treats documents like scattered data points. Real enterprise knowledge is a network of relationships, dependencies, and chains of logic.
Add multi-tenant deployments, domain-specific jargon, evolving knowledge bases, and strict latency SLAs—and you understand why Standard RAG is not just underperforming. It's structurally mismatched with what enterprises actually need.
"The companies winning with AI in 2026 are not the ones with the most documents in their vector store. They are the ones who stopped trusting Standard RAG to do the heavy lifting."
Quick Self-Assessment: Is Your RAG Broken?
Check all that apply:
- Users report answers that sound confident but are factually wrong
- System struggles with questions spanning multiple documents
- Queries about recent data frequently hallucinate details
- Latency is unpredictable; some queries take 10+ seconds
- You're spending engineering effort "tweaking" retrieval every sprint
- Users increasingly distrust AI outputs for decision-making
If you checked 3+, your retrieval architecture is limiting your ROI. That's when architectural upgrades compound to measurable ROI. Let's diagnose what's actually broken →
Five Architectures That Are Taking Their Place
1. Graph-Enhanced RAG: Reasoning Over Proximity
Instead of treating a knowledge base as a flat collection of text, Graph-Enhanced RAG maps entities, relationships, and dependencies into a structured graph. When a query arrives, the system traverses edges rather than searching by proximity, enabling multi-hop reasoning that Standard RAG can never achieve.
Real-world impact:
- Financial services firms answer complex portfolio questions across holdings, regulations, and market conditions simultaneously
- Legal tech platforms navigate clause dependencies and precedent chains
- Healthcare systems reason across patient history, medications, and diagnostic protocols
- Manufacturing tracks component sourcing, supplier relationships, and regulatory compliance across supply chains
When it wins: Any domain where knowledge is inherently relational. The more your questions require "A connects to B connects to C" reasoning, the more dramatic the improvement.
Latency profile: Higher upfront cost (graph construction), but query latency is often faster than RAG because you traverse precise relationships instead of searching millions of vectors.
2. Agentic RAG: The Research Analyst Inside Your Retrieval Loop
Agentic RAG embeds an LLM inside the retrieval process itself. Rather than performing a single retrieve-then-generate cycle, the system iteratively plans, retrieves, reasons, and decides whether it has enough information before answering. Think of it as replacing a library search with a research analyst who keeps pulling new sources until the question is truly answered.
The iterative loop:
- User asks question
- LLM plans retrieval strategy
- System fetches initial sources
- LLM evaluates: "Do I have enough?"
- If no → Fetch additional context
- If yes → Generate answer
Real-world impact:
- Open-ended research tasks complete 40-60% faster with higher completeness
- Analytical queries on complex datasets produce thorough, multi-faceted answers
- Users get transparency: the system explains which sources informed each part of the answer
- Hallucinations drop dramatically because the agent halts before inventing details
This architecture is particularly powerful for:
- Market research and competitive intelligence
- Technical documentation and debugging
- Business analytics and reporting
- Academic and investigative research
When to use: Complex analytical queries, open-ended research, any task where "good enough" answers are expensive but "thorough" answers drive decisions.
3. Hierarchical and Contextual Chunking: Preserve Structure, Gain Precision
Next-generation systems are abandoning fixed-size chunking in favor of intelligent document parsing—preserving section boundaries, heading hierarchies, table structures, and cross-references. Parent-child chunk relationships allow retrieval at multiple levels of granularity.
How it works:
- Parse documents into a tree structure: Sections → Subsections → Paragraphs
- Retrieve summary chunks first (broad context)
- Expand into detail chunks only when needed (precision without bloat)
- Preserve references between chunks (tables link to supporting paragraphs, clauses reference definitions)
Real-world impact:
- Answer precision improves 25-40% with no loss of recall
- Retrieval is faster (summary chunks are smaller)
- Context is richer (the system knows why chunks are related)
- Users understand answer provenance better (chunk hierarchy maps to document structure)
Ideal for: Product documentation, technical manuals, contracts, regulations, legal discovery—any domain where document structure encodes meaning.
4. Hybrid Retrieval with Machine Learning Re-ranking: Close the Vocabulary Gap
Combining dense vector search with sparse keyword search (BM25 or similar) closes the vocabulary gap that pure embedding-based systems suffer. A strong machine learning re-ranker then re-scores retrieved candidates using cross-attention, dramatically improving the relevance of what ultimately reaches the generation layer.
The architecture:
- Dense retrieval (vectors) captures semantic similarity
- Sparse retrieval (keywords/BM25) captures exact term matches
- ML re-ranker evaluates both sets via cross-attention
- Top-ranked candidates pass to generation layer
Why this works:
- Vectors miss queries where exact terminology matters (medical terms, technical jargon, compliance language)
- Keywords miss paraphrased content
- Combined + re-ranked catches both
Real-world impact:
- Relevance precision increases 20-35% over vector-only retrieval
- This is table stakes for serious production pipelines
- Latency is predictable (re-ranker is lightweight)
- Cost is reasonable (third-party re-ranking APIs cost pennies per query)
Ideal for: Enterprise search where terminology precision matters. Healthcare, legal, finance, technical support—anywhere users have domain vocabulary expectations.
5. Talk to Data: Turn Questions Into Computed Answers
Talk to Data architectures go beyond document retrieval entirely. Rather than searching static text, they allow a language model to generate and execute queries against structured databases, APIs, and live data streams in real time. When a user asks, "What were our top-performing SKUs last quarter compared to this one?"—the system does not search for an answer; it computes one.
How it works:
- User asks a natural language question
- System generates SQL/API query
- Query executes against live data
- Results synthesize into a natural language answer
Real-world impact:
- Answers are always current (computed, not retrieved)
- No hallucination risk for factual queries (results come from your database)
- Query patterns reveal usage insights
- Non-technical users get direct database access without learning SQL
This is rapidly becoming one of the most commercially valuable AI capabilities for data-driven organisations:
- Sales teams access real-time pipeline data without analyst overhead
- Finance teams query GL data directly ("What was Q3 spend by cost center?")
- Operations teams monitor KPIs in natural conversation
- Executives gain insights without waiting for report requests
Ideal for: Any organization with structured data, databases, or APIs. The ROI is direct: reduce report generation overhead, democratize data access, enable faster decisions.
RAG Architecture Comparison: Which One Is Right for Your Use Case?
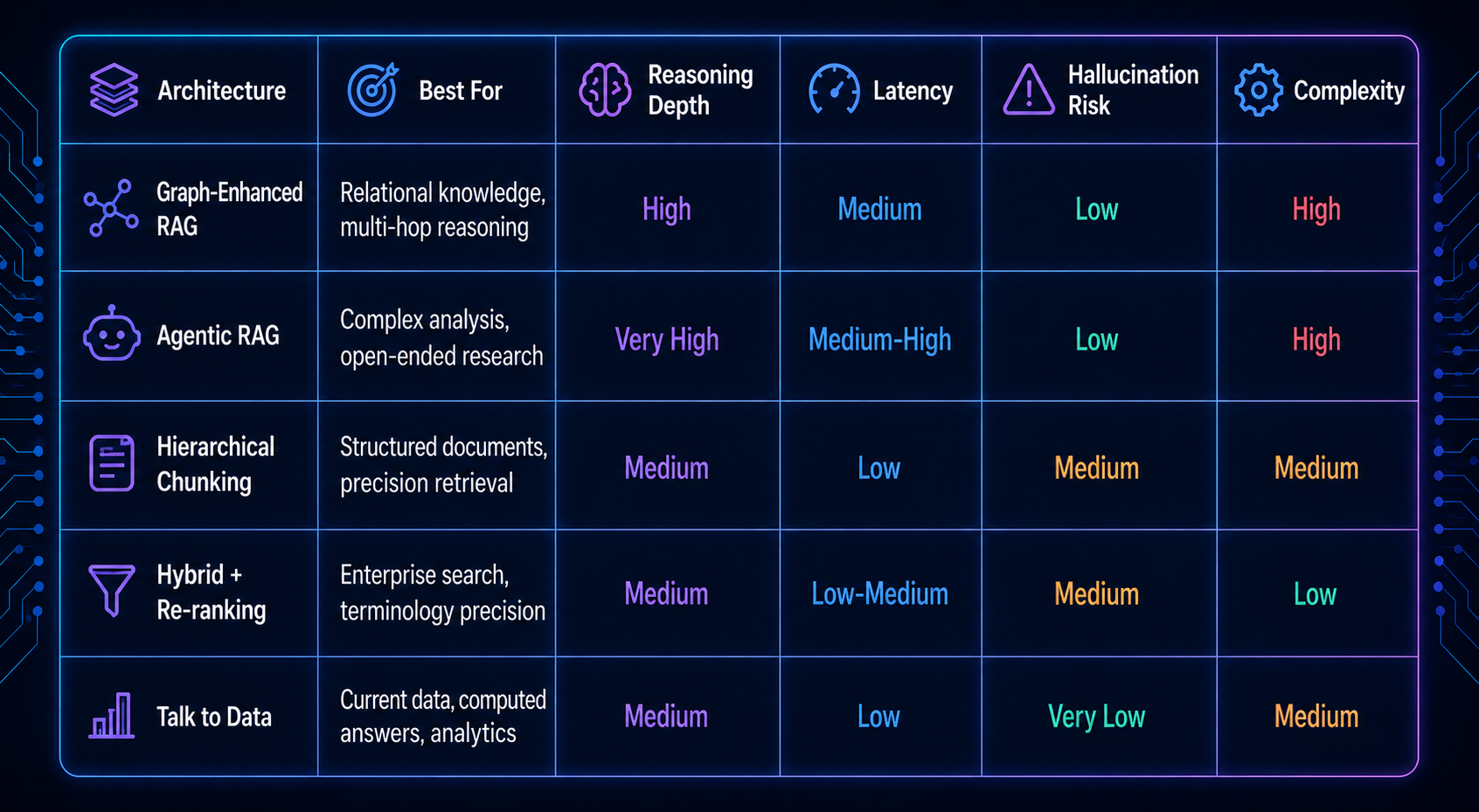
Still unsure which path fits your data topology? Book a 30-min architecture consultation →
The Evaluation Problem No One Talks About
One of the most overlooked reasons Standard RAG persists in organizations is that it's genuinely difficult to measure RAG failure. If your system retrieves wrong chunks and your LLM confidently synthesizes them into a plausible-sounding but incorrect answer, traditional accuracy metrics won't catch it.
The Silent Cost of Bad Evaluation:
- Users make decisions based on hallucinated data
- The wrong answer is confident—so no one questions it
- By the time you discover the error, it's driven business decisions
- Traditional metrics (precision, recall) don't catch faithfulness
Next-generation systems are being built alongside new evaluation frameworks—machine learning-powered judges that assess:
- Faithfulness: Is every claim grounded in retrieved sources?
- Groundedness: Are inferences justified by the data?
- Completeness: Does the answer address all aspects of the question?
Without a robust evaluation infrastructure, organizations swap one broken system for another. The architecture upgrade and the evaluation upgrade must happen together.
This is a cultural shift as much as a technical one. Teams that move beyond Standard RAG successfully are those that treat AI reliability as an engineering discipline with measurable standards—not a prompt engineering exercise.
Upgrade Without Ripping Out Everything
The migration path is not a full rebuild.
Intelligent teams audit existing pipelines, identify the failure modes costing them the most, and prioritize targeted architectural upgrades. A typical roadmap looks like:
Phase 1 (2-3 weeks): Add hybrid retrieval + re-ranking
- Cost: Low ($5-15K implementation)
- Impact: 20-35% precision improvement
- Risk: Minimal (additive, not replacing)
Phase 2 (4-6 weeks): Implement hierarchical chunking
- Cost: Medium ($20-40K implementation)
- Impact: 25-40% precision gain, 15% latency reduction
- Risk: Low (applies to new ingestion forward)
Phase 3 (6-10 weeks): Build Talk to Data layer
- Cost: Medium ($30-50K implementation)
- Impact: 60-80% reduction in "basic fact" queries, faster analytics
- Risk: Low (runs parallel, users opt-in)
Phase 4 (8-12 weeks): Graph-Enhanced RAG for relational domains
- Cost: High ($50-100K+ depending on domain)
- Impact: Multi-hop reasoning, 40%+ improvement in complex questions
- Risk: Medium (requires schema design, but worth it for domains where it fits)
Each phase compounds. By month 4, you're no longer debugging RAG—you're operating a sophisticated, multi-modal retrieval system that catches what Standard RAG always missed.
How Talk to Data Unlocks Real Business Value
While architectural upgrades improve retrieval quality, Talk to Data unlocks an entirely different value stream: the ability to turn business questions into instant, computed answers.
Consider the typical enterprise scenario:
- A sales director needs "our top 5 deal sources by pipeline value"
- Under Standard RAG, she searches through (hallucinated or outdated) sales documents
- Under Talk to Data, she asks the system, which queries your CRM in real time and returns exact numbers
The difference isn't just speed. It's trust, accuracy, and decision velocity.
Explore how Talk to Data transforms analytics workflows →
What This Means for Your AI Strategy in 2026
Organizations still anchored to vanilla RAG pipelines are not just falling behind technically—they're accumulating AI debt. Every quarter spent patching a fundamentally flawed retrieval system is a quarter competitors spend building more capable architectures on top of sounder foundations.
The timeline is tightening:
- By the end of 2026, production RAG pipelines will be seen as legacy
- By 2027, deploying new systems without architectural sophistication will be a red flag
- By 2028, the competitive gap between old RAG and next-gen architectures will be unrecovarable
The good news: these decisions don't require perfect information. They require deep expertise in:
- Diagnosing which architecture genuinely fits your data topology
- Selecting the right sequencing for your upgrade path
- Building evaluation frameworks that prevent swapping one broken system for another
Choosing the wrong architecture for your data, query distribution, or latency constraints can produce systems that are harder to debug than the Standard RAG pipelines they replaced. This is exactly where an experienced AI solutions partner creates disproportionate value.
How Leading Organisations Are Making the Transition
The shift away from Standard RAG isn't theoretical. It's happening now:
Financial Services: Graph-Enhanced RAG enables portfolio managers to reason across holdings, regulations, and market scenarios in seconds—revealing risks and opportunities vanilla RAG always missed.
Legal Tech: Hierarchical chunking + graph reasoning lets paralegals navigate regulatory changes and precedent chains that previously required senior attorney oversight.
Healthcare: Agentic RAG iterates through patient history, medications, and protocols, ensuring diagnostic recommendations are thorough and traceable to clinical evidence.
E-Commerce: Talk to Data lets merchandisers access real-time inventory, demand, and pricing without data analyst bottlenecks.
The common thread: these organizations stopped treating AI as a demo project and started treating it as production infrastructure. Architecture choices compound.
The Role of AI Expertise in This Transition
For most enterprises, the gap between understanding that Standard RAG is failing and knowing what to build instead is significant. This is where expert AI engineering becomes not just helpful but strategically essential.
The decisions that matter:
- Which retrieval paradigm for your knowledge structure?
- Which chunking strategy for your document types?
- Which evaluation framework to prevent shipping hallucinations?
- Which infrastructure to handle scale without exploding cost?
These decisions compound over time. Good decisions create leverage. Poor decisions create drag.
The best LLM architectures in 2026 are not off-the-shelf solutions. They're engineered for specific knowledge structures, query patterns, and business constraints. That engineering requires both theoretical depth and substantial production experience—a combination that only comes from teams who've built and iterated on these systems across diverse real-world deployments.
The Window for Action Is Narrowing
The enterprise AI landscape is moving fast. The gap between organizations with production-grade retrieval architectures and those still debugging Standard RAG is widening every quarter.
The good news: The path forward is clearer than ever.
- Successor architectures are proven
- Tooling is maturing
- Evaluation methodologies are increasingly well understood
- Your migration doesn't require a rewrite—it requires smart sequencing
What remains is the decision to act. If your AI systems are underperforming and you suspect your retrieval layer is the culprit, it almost certainly is.
The question is not whether to move beyond Standard RAG. The question is, how quickly can you do it without rebuilding everything from scratch?
Moving Beyond the Hype: Build the Future with NeuraMonks
Bottom line: Standard RAG is dead. The question is whether you're building with next-generation architectures or still debugging 2024's broken patterns. The gap between the two is growing every quarter.
Let's close it.
If you are ready to move past fragile demos and deploy enterprise-grade intelligence, explore how we are helping organizations scale across four critical pillars:
- LLM Capabilities & Development: Custom fine-tuning, domain-specific alignment, and optimization to ensure your models possess deep foundational knowledge of your industry.
- Agentic AI Systems: Moving past static, linear pipelines. We build autonomous agents that plan, self-correct, use specialized tools, and reason iteratively until they deliver flawless results.
- Machine Learning Re-ranking & Evaluation: Implementing advanced cross-encoders to eliminate noise from your data retrieval, coupled with automated testing rigs to guarantee zero hallucinations in production.
- Talk to Data: Query your business in natural language. We turn complex natural language into real-time database queries, giving your non-technical leadership instant, secure, and computed business intelligence.
Schedule Your Diagnostic Consultation →]
Get Your Free RAG Architecture Audit
Your retrieval pipeline is either a competitive advantage or a liability. There is no middle ground in 2026.
In 60 minutes, we'll:
- Diagnose your current retrieval system's failure modes
- Map which architecture fits your knowledge structure
- Build a 12-week roadmap with clear milestones and ROI
- Identify quick wins (2-3 weeks) vs. longer strategic builds
No sales pitch. Just expertise.
NeuraMonks: From Diagnosis to Production-Grade Architectures
The most sophisticated AI systems don't start with a template—they start with a diagnosis.
At NeuraMonks, we've helped organisations across industries move beyond Standard RAG by:
1. Auditing — Deep analysis of knowledge structure, query patterns, failure modes, and business constraints
2. Architecting — Selecting the right combination of Graph-Enhanced, Agentic, Hybrid, and Talk to Data approaches for your specific context
3. Building — Implementing with production-grade evaluation frameworks from day one, not retrofitted after deployment
4. Operating — Optimizing retrieval quality, latency, and cost as query patterns evolve
Engagements typically combine:
- Graph-Enhanced retrieval for complex relational knowledge
- Hybrid search + ML re-ranking for high-recall enterprise search
- Agentic reasoning layers for open-ended analytical workflows
- Talk to Data integration for real-time, computed answers
The teams that have moved through this process report not just improved answer quality, but fundamentally more trustworthy AI systems—ones where users stop second-guessing outputs and start relying on them for real decisions.
Ready to Replace Your Broken RAG?
Every day your enterprise operates on Standard RAG is a day your competitors gain ground.
NeuraMonks helps enterprises design, build, and deploy next-generation AI retrieval systems engineered specifically for your knowledge structure, query patterns, and business goals.
What you get:
- Free RAG diagnostic audit
- Custom architecture roadmap with ROI projections
- Production-ready delivery with built-in evaluation
- Ongoing optimization and scaling

Ketan Kanjiya
Ketan Kanjiya is a Machine Learning researcher and Chief Research Officer at Neuramonks, an AI-focused technology company based in Ahmedabad, Gujarat. With hands-on expertise in AI/ML, image processing, and web application development, he has led research initiatives across F(x) Data Labs and Kshatrainfotech. Ketan writes to simplify advanced technical concepts for developers and tech enthusiasts alike.