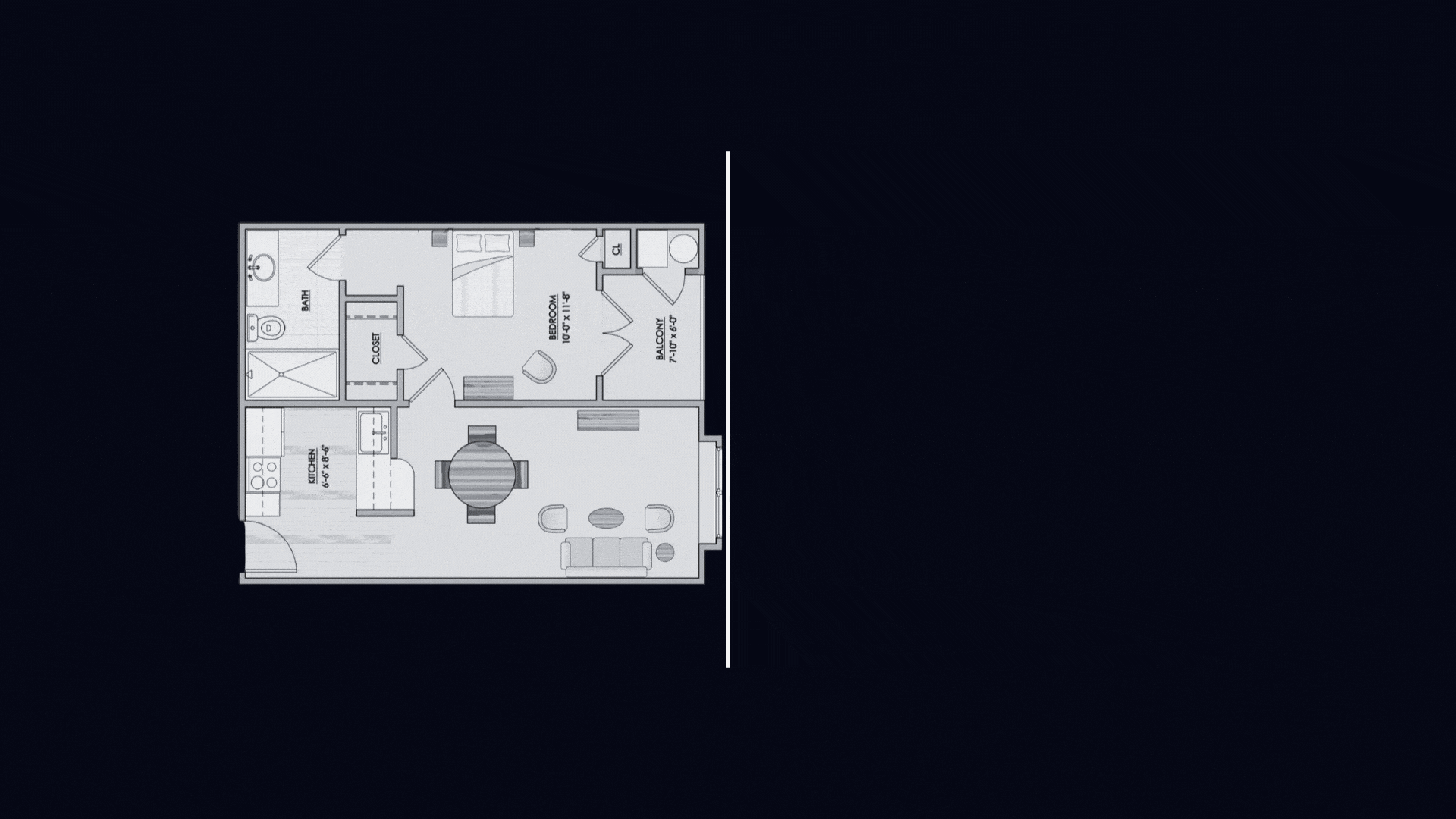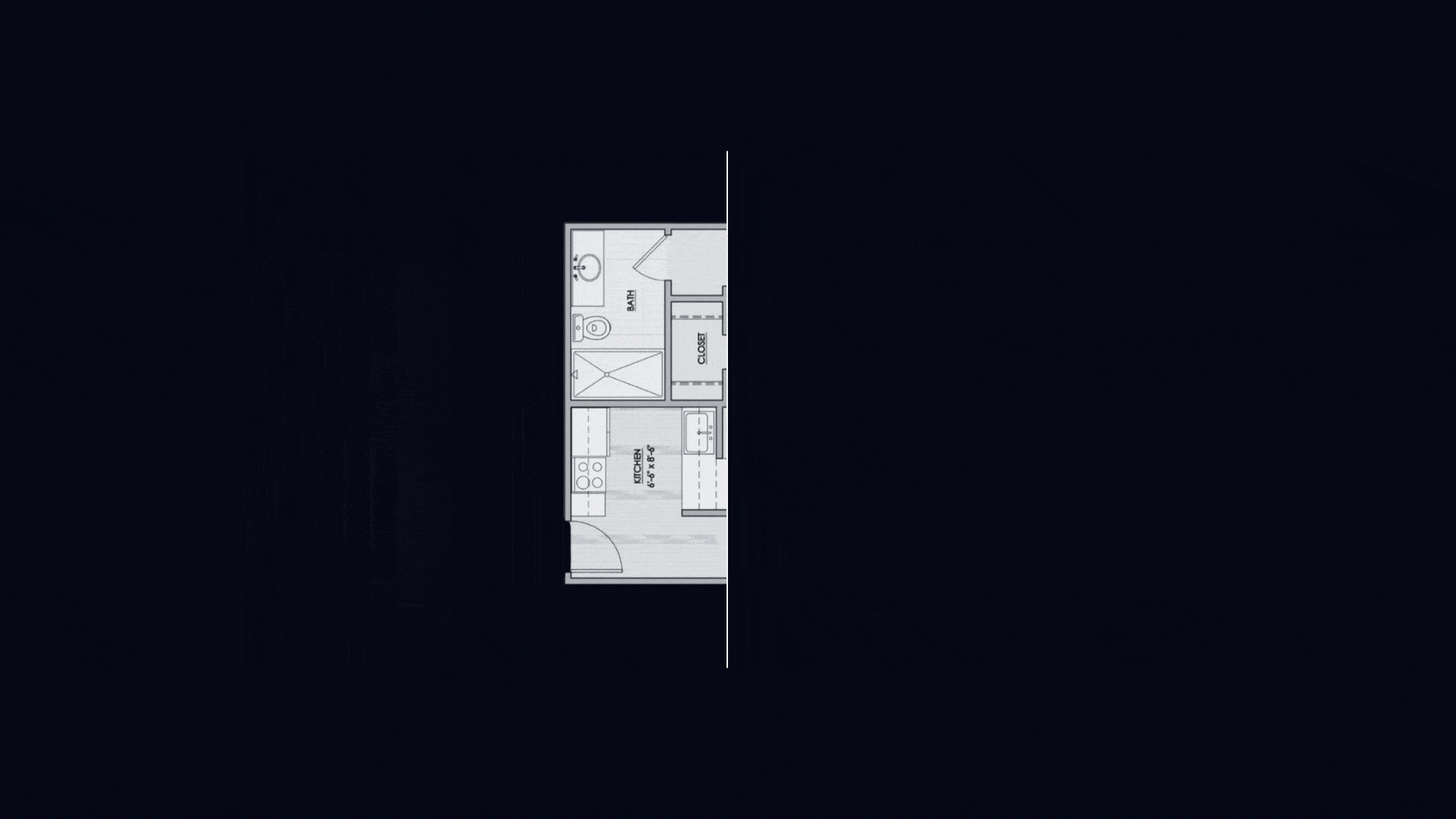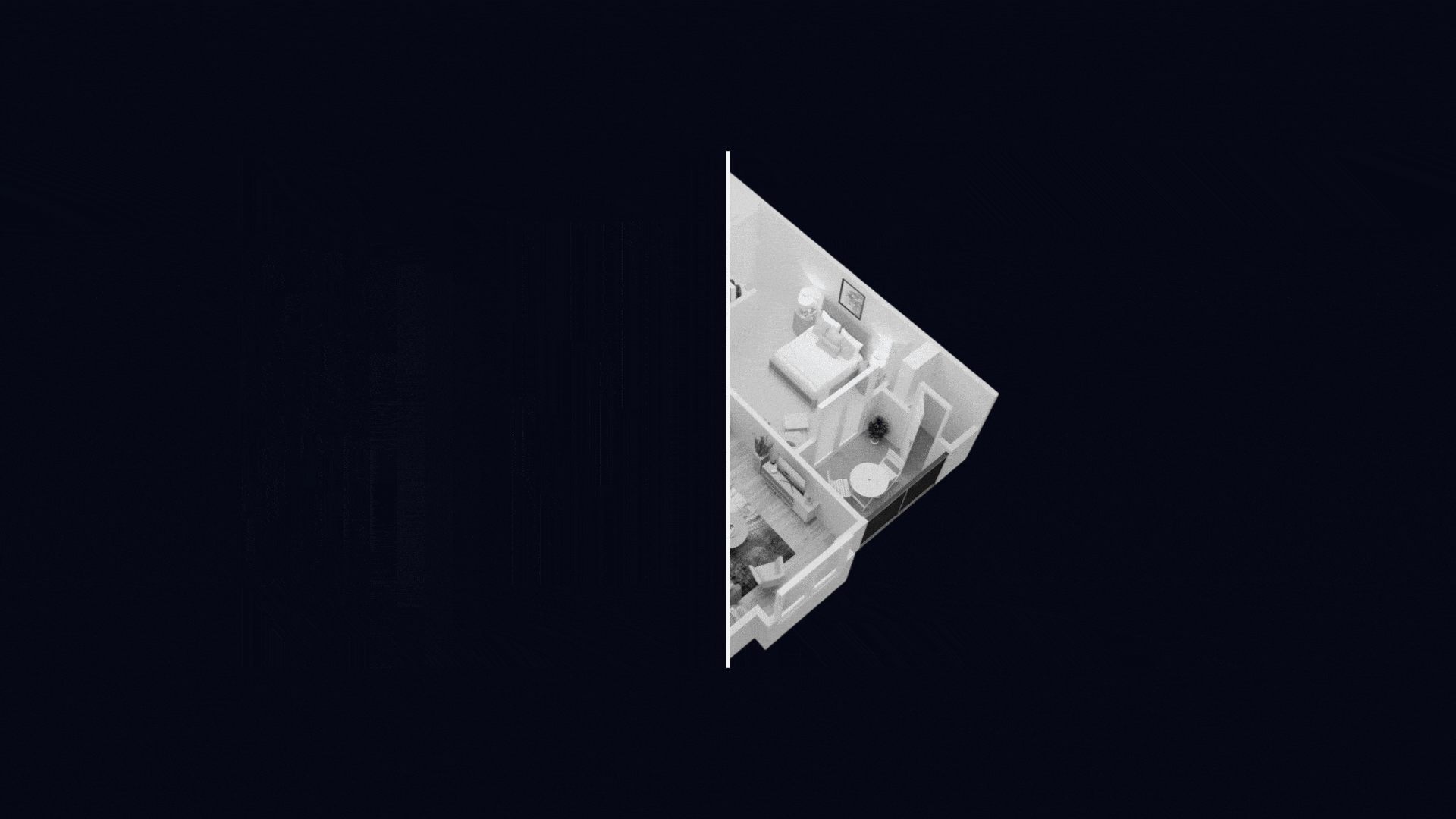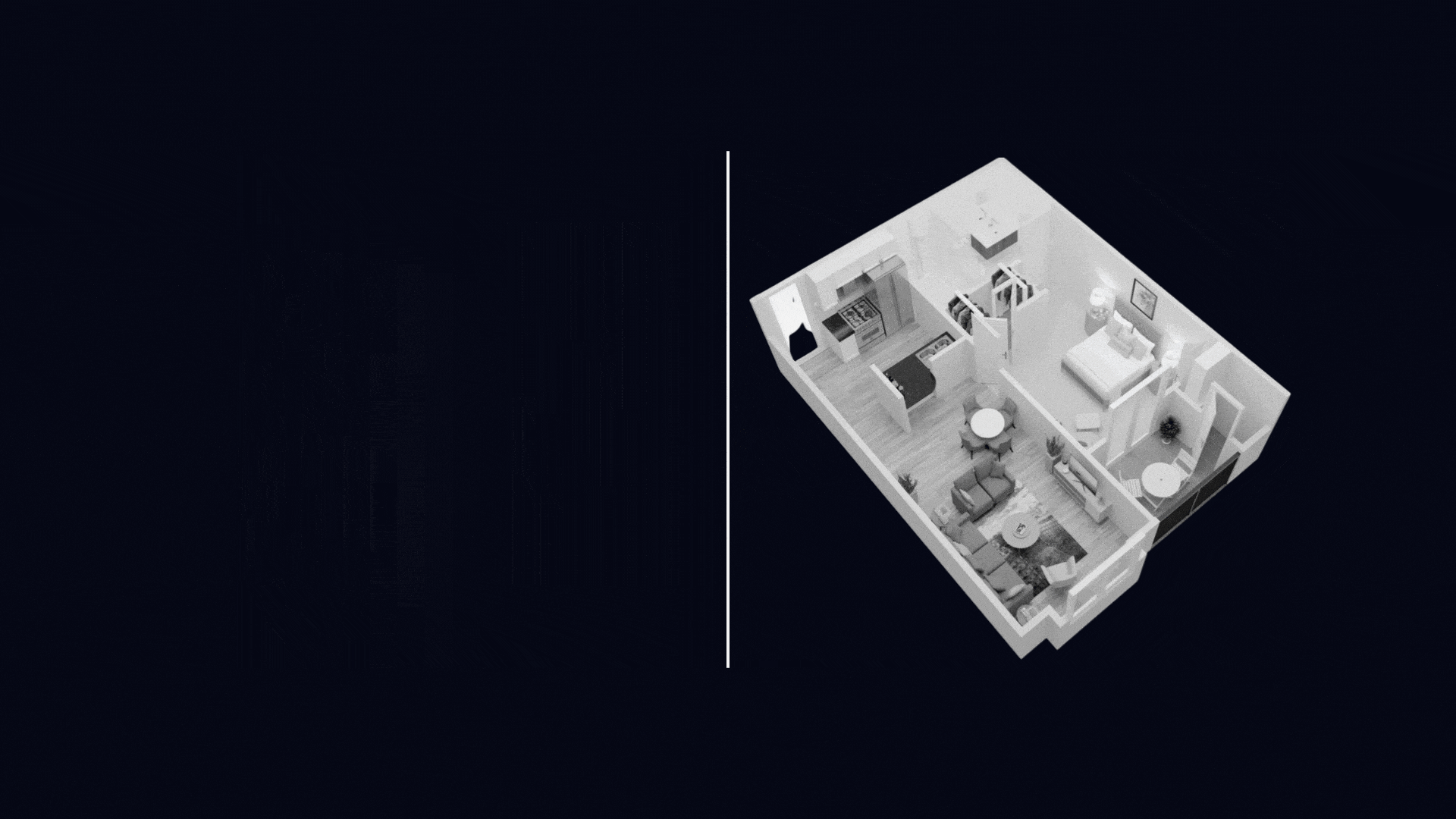
Converts raw image into editable floor plans, explore renovation ideas, and seamlessly turn concepts into reality



Trusted by 100+ Clients Worldwide
We've shipped over 100+ AI models across healthcare, construction, and manufacturing. If your team is still running on manual workflows and gut-feel decisions, we can change that without replacing your existing stack.


As a custom AI Solutions company, we've engineered features that will actually make a difference to your business.
Converts raw image into editable floor plans, explore renovation ideas, and seamlessly turn concepts into reality

Dive into videos with dynamic, interactive segments—explore, customize, and engage with content tailored just for you.
Interactive Navigation
Explore video paths with 30–40% deeper engagement
Customizable Experience
AI-generated paths cut effort by 55–65%
Engaging Storytelling
Scale storytelling with 35% more engagement depth.

Streamlined COVID Testing with Secure Results Management for Safer Travel.

AI-Powered Font Recognition
Real-time font detection with 80% Top-10 accuracy at massive scale.
Scalable Matching Engine
Onboard 100% new fonts without retraining, enabling 40% faster scaling.
Design-Centric Integration
Deliver 95% precision with 30% smoother UI integration

Create standout resumes with ATS Scoring, match them to jobs, and manage updates with ease.
AI Product Advisor
Recommends from 30,000+ fishing products, cutting discovery time by 40 to 50%.
Domain-Trained Chatbot
Delivers expert-level guidance with 30 to 40% higher buyer confidence.
Sales-Driven Suggestions
Boosts ecommerce conversions by 20 to 30% and reduces decision fatigue
Clients, stakeholders, and partners empowering technology to work in the real world!
.webp)

.webp)
.webp)
.webp)






100% Confidential & NDA-Protected
Real results from real clients. These aren't projections they're measured outcomes from deployed systems.
From your first idea to a live, revenue generating AI system we handle every phase.

AI consulting for enterprises assists in shaping and implementing AI strategies aligned with your goals. We assist with solution discovery, technology and infrastructure alignment.
We deliver rapid prototypes that prove AI works in your environment, reducing risk and building stakeholder confidence.
Launch products swiftly with AI-driven MVP development to test and refine your business vision. We assist you to build AI products for market launch and real-world applications.
End-to-end AI solutions crafted to turn your innovative concepts into robust, scalable products.

Evaluate your organization’s data, processes, and tech maturity.
Pinpoint AI initiatives that deliver maximum business value and operational efficiency.
Make sure your systems are prepared for the scale of artificial intelligence.
Map actionable steps for fast, risk-free deployment.
Risk & Compliance Analysis: Guarantee security, governance, and regulatory alignment.
Prototype Development
Build AI-driven prototypes to validate your concept.
Feasibility Analysis
Assess the technical and business feasibility of your idea.
Market Validation
Conduct real-world testing to evaluate user demand.
Technology Stack Selection
Choose the best frameworks and tools for implementation.
Performance Benchmarking
Compare with industry standards to ensure effectiveness.
Rapid Development
Build and launch a functional AI-driven MVP swiftly.
Core Feature Integration
Focus on essential functionalities for initial testing.
User Feedback & Iteration
Gather insights to refine the product.
Scalability Planning
Ensure a smooth transition from MVP to full-scale product.
Deployment Readiness
Prepare for real-world application and market launch.
End-to-End AI Solutions
Comprehensive development from ideation to execution.
Custom AI Models
Tailor-made AI models for unique business requirements.
Wrapper Creation
Build API wrappers and middleware to integrate AI into your existing systems.
Performance Optimization
Ensure high efficiency and accuracy.
Security & Compliance
Implement best practices for data protection.
Consultation
Expert guidance to shape and implement AI strategies aligned with your goals.
AI Readiness Assessment
Evaluate your current setup to determine AI implementation feasibility.
Use Case Identification
Discover the best AI applications tailored to your business needs.
Technology & Infrastructure Planning
Design a scalable and efficient AI architecture.
Implementation Strategy
Create a step-by-step roadmap for smooth AI adoption.
Risk & Compliance Analysis
Ensure data security, regulatory compliance, and ethical AI practices.
Proof Of Concept
Validate your AI ideas with tailored prototypes that showcase feasibility and potential.
Prototype Development
Build AI-driven prototypes to validate your concept.
Feasibility Analysis
Assess the technical and business feasibility of your idea.
Market Validation
Conduct real-world testing to evaluate user demand.
Technology Stack Selection
Choose the best frameworks and tools for implementation.
Performance Benchmarking
Compare with industry standards to ensure effectiveness.
Minimum Viable Product
Launch fast with impactful, AI-driven MVPs to test and refine your vision.
Rapid Development
Build and launch a functional AI-driven MVP swiftly.
Core Feature Integration
Focus on essential functionalities for initial testing.
User Feedback & Iteration
Gather insights to refine the product.
Scalability Planning
Ensure a smooth transition from MVP to full-scale product.
Deployment Readiness
Prepare for real-world application and market launch.
Product Development
End-to-end AI solutions crafted to turn your innovative concepts into robust, scalable products.
End-to-End AI Solutions
Comprehensive development from ideation to execution.
Custom AI Models
Tailor-made AI models for unique business requirements.
Wrapper Creation
Build API wrappers and middleware to integrate AI into your existing systems.
Performance Optimization
Ensure high efficiency and accuracy.
Security & Compliance
Implement best practices for data protection.
We deliver Enterprise AI Solutions designed for real-world performance — secure, scalable, and aligned with operational and revenue objectives.


We build AI that delivers results, not experiments. From strategy to deployment, we own 100% execution driving 30 to 40% efficiency gains within the first 90 days.
AI solutions across 6+ industries, reducing implementation risk by 25% with proven frameworks.
Our AI systems run across regions with 99.9% uptime, ensuring secure, consistent performance for distributed enterprise teams worldwide
We take AI from idea to production in 4 to 8 weeks, helping enterprises launch 50% faster without compromising quality or accuracy.
Every project is led by senior AI architects, aligning technology with growth, automation, and cost savings delivering 20 to 35% operational cost reduction.
Over 90% of our AI projects scale from pilot to production because we deliver AI that works and generates measurable ROI.
Backed by 48+ dedicated engineers, we provide live monitoring and proactive retraining across 200+ active deployments. With 8 years of infrastructure expertise, we catch performance drift before it hits your users keeping downtime at near zero.

We work in industries where AI delivers clear, measurable ROI not theoretical gains.


From AI Solutions and AI/ML company rankings to Agentic AI and automation strategies our latest blogs give you the clarity and confidence to make smarter AI decisions.
Still got questions? Feel free to reach out to our incredible
support team, 7 days a week.
How much does it cost to build a custom AI solution?
Projects start under $5,000 for a scoped POC. Full builds range $10,000 $25,000+ depending on complexity, integrations, and scale. We size every engagement to your actual needs.
What's the difference between AI consulting and AI development?
Consulting defines what to build and whether it's worth building. Development is the actual build — models, APIs, data pipelines, and deployment. At NeuraMonks, we offer both as a single engagement, so there's no handoff gap between strategy and execution.
How long does AI development take?
Four to eight weeks from proof-of-concept to production deployment. That's about 50% faster than the industry average. The timeline depends on data readiness, integration complexity, and how much of your existing stack we're working with.
What ROI can I realistically expect from AI?
Clients consistently report 30–40% efficiency gains within the first 90 days and 20–35% reduction in operational costs. Over 90% of our pilot projects reach full production — which means the ROI compounds, not disappears after the demo.
Can AI integrate with my existing software and workflows?
Absolutely. We integrate AI into your existing systems via APIs, wrappers, and agents, automating workflows without replacing your stack, cutting manual effort by 30 to 50%.
Do you work with startups or only large enterprises?
Both. We work with funded startups and global enterprises. Engagements scale from a focused $5K POC to full enterprise AI platform builds backed by 48+ specialists.
Is my data safe? Are you ISO certified?
Yes. As an enterprise AI development company with offices in the USA, UAE, and India, we operate under ISO 27001 certification and SOC 2 compliance. Every engagement is covered by a signed NDA before any data is shared. Your IP stays yours we don't train models on your data for other clients.
What is Agentic AI and how does it help businesses?
Agentic AI refers to AI systems that can independently plan and execute multi-step tasks — browsing data, writing reports, triggering actions in other systems without a human managing each step. For businesses, this means entire workflows (research, customer follow-up, reporting) can run autonomously at any hour.
Free, No Commitment
Share your vision. Our senior AI architects will map it into a concrete technical plan, delivered to your inbox within 24 hours.
Response within 24 hours, guaranteed
100% NDA-protected & confidential
200+ AI Models in Production
48+ AI & Cloud Specialists
100+ clients already scaled with us





.webp)

.webp)

.webp)