.webp)




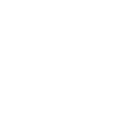








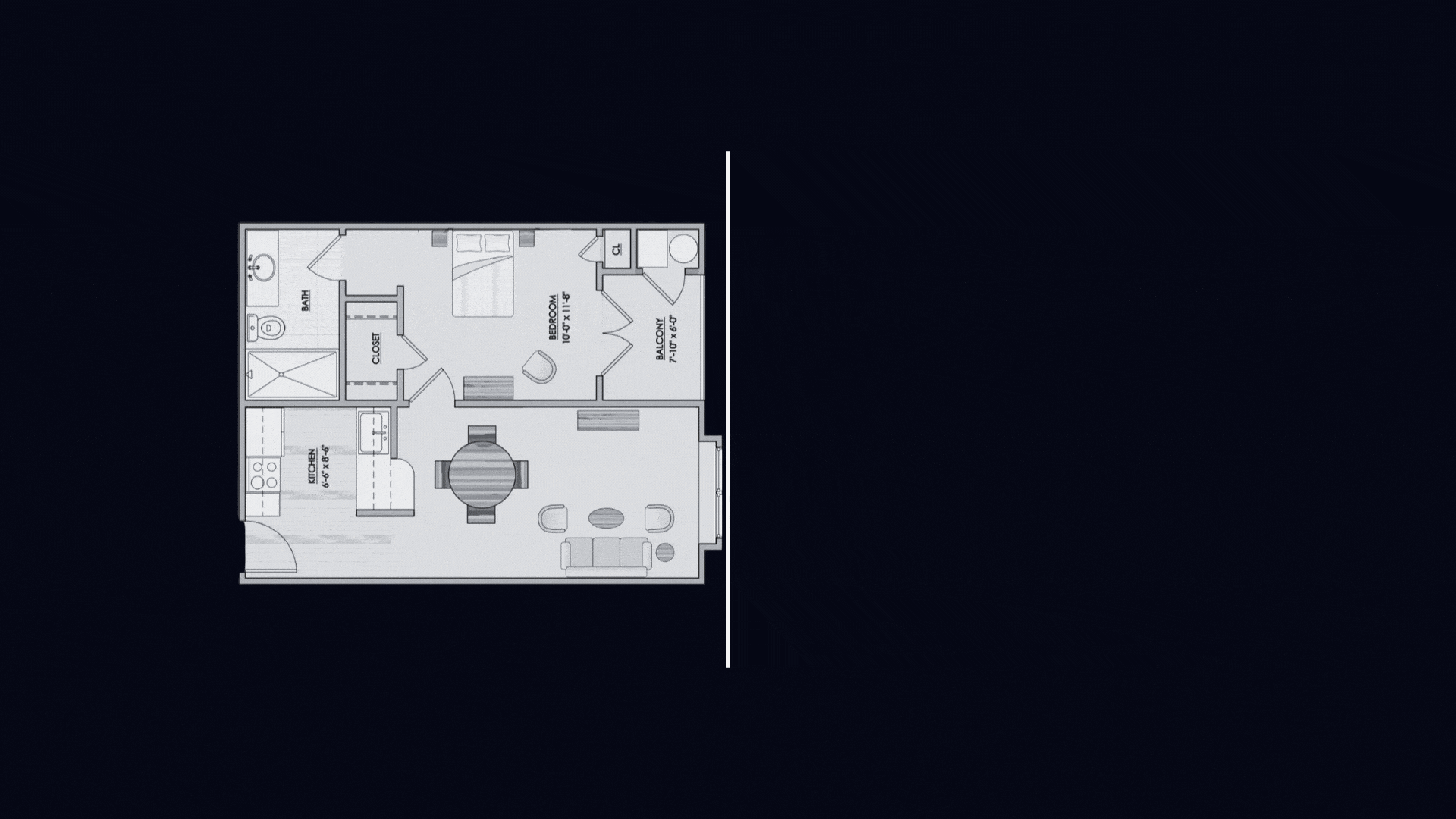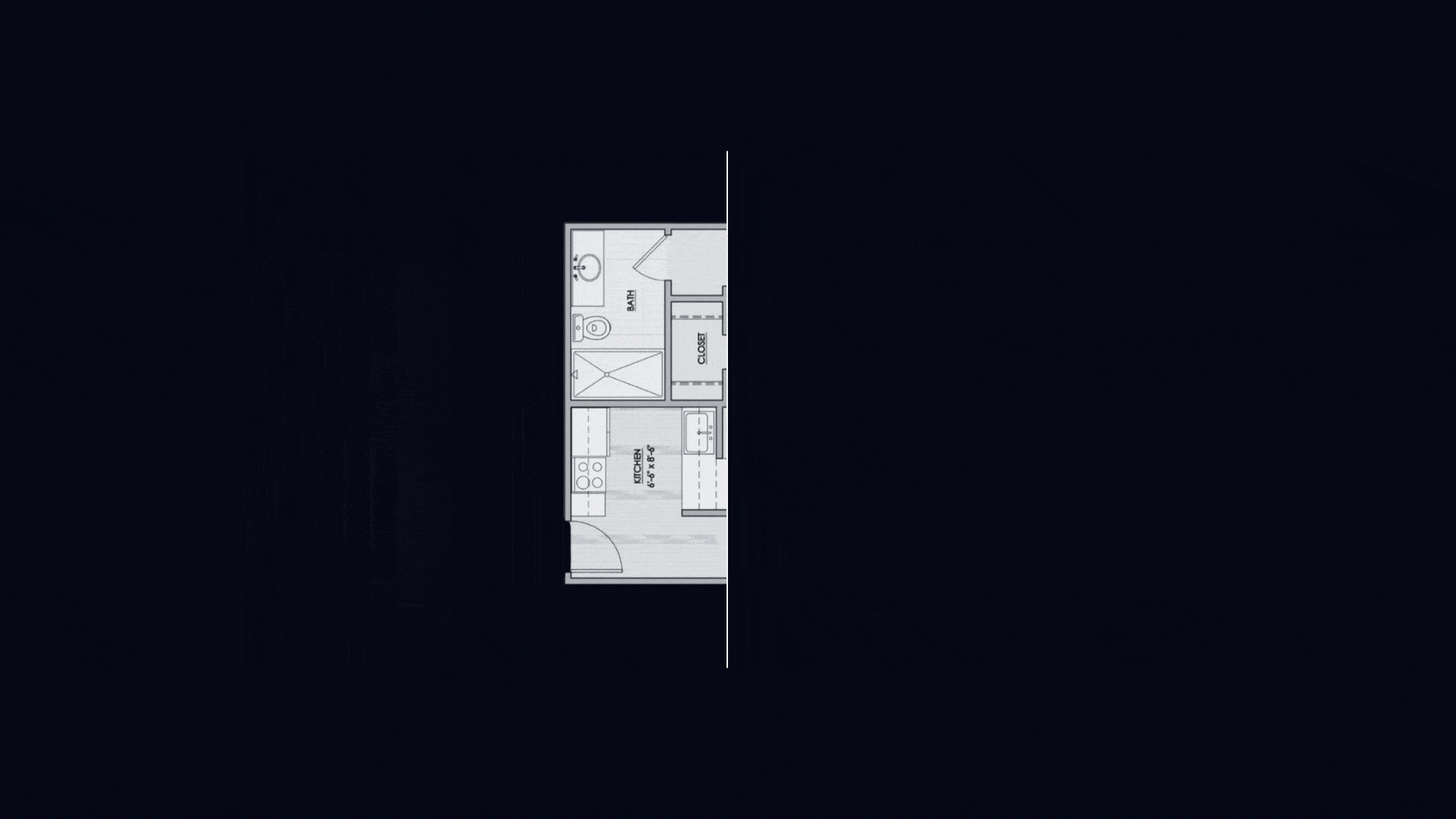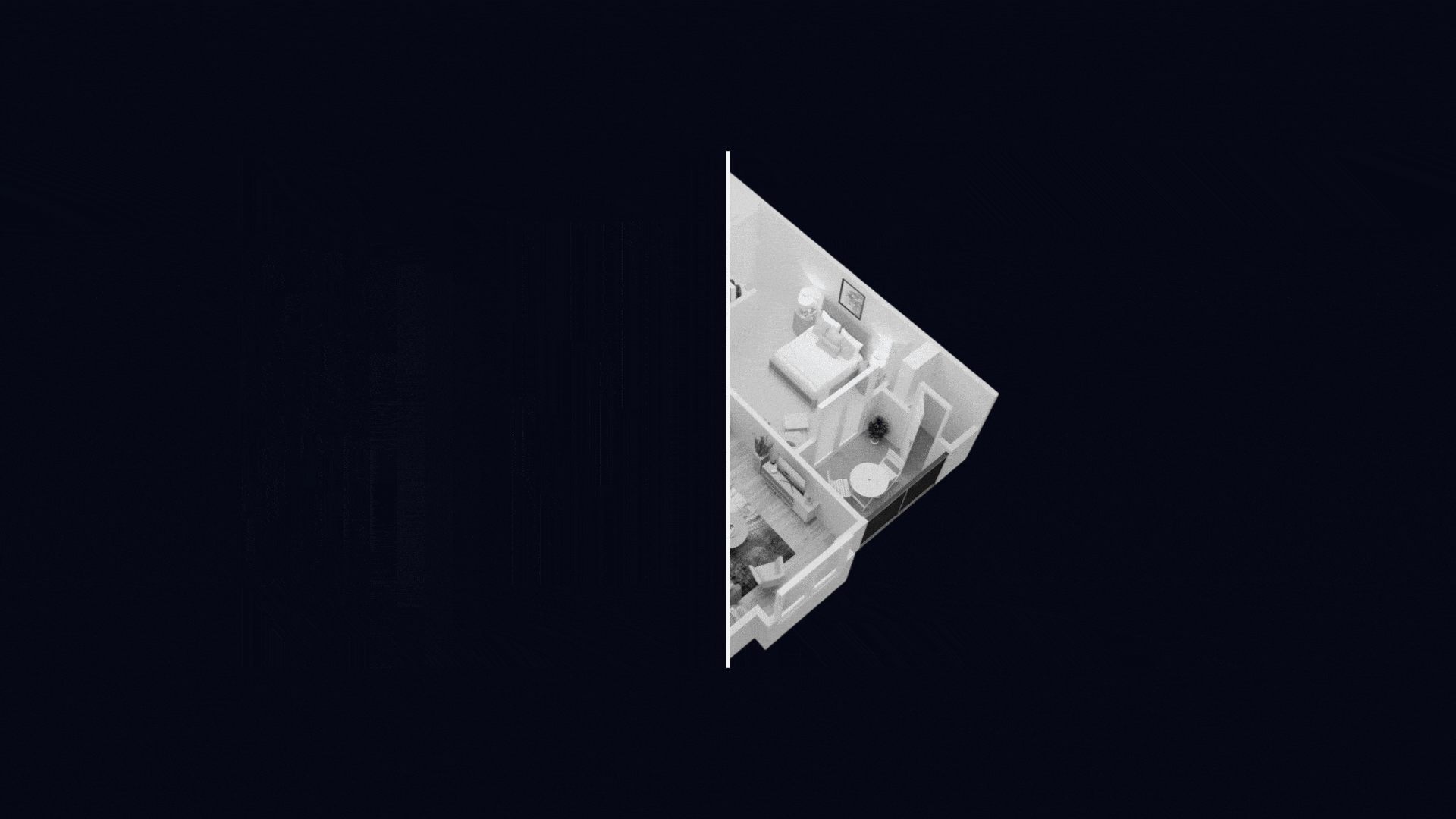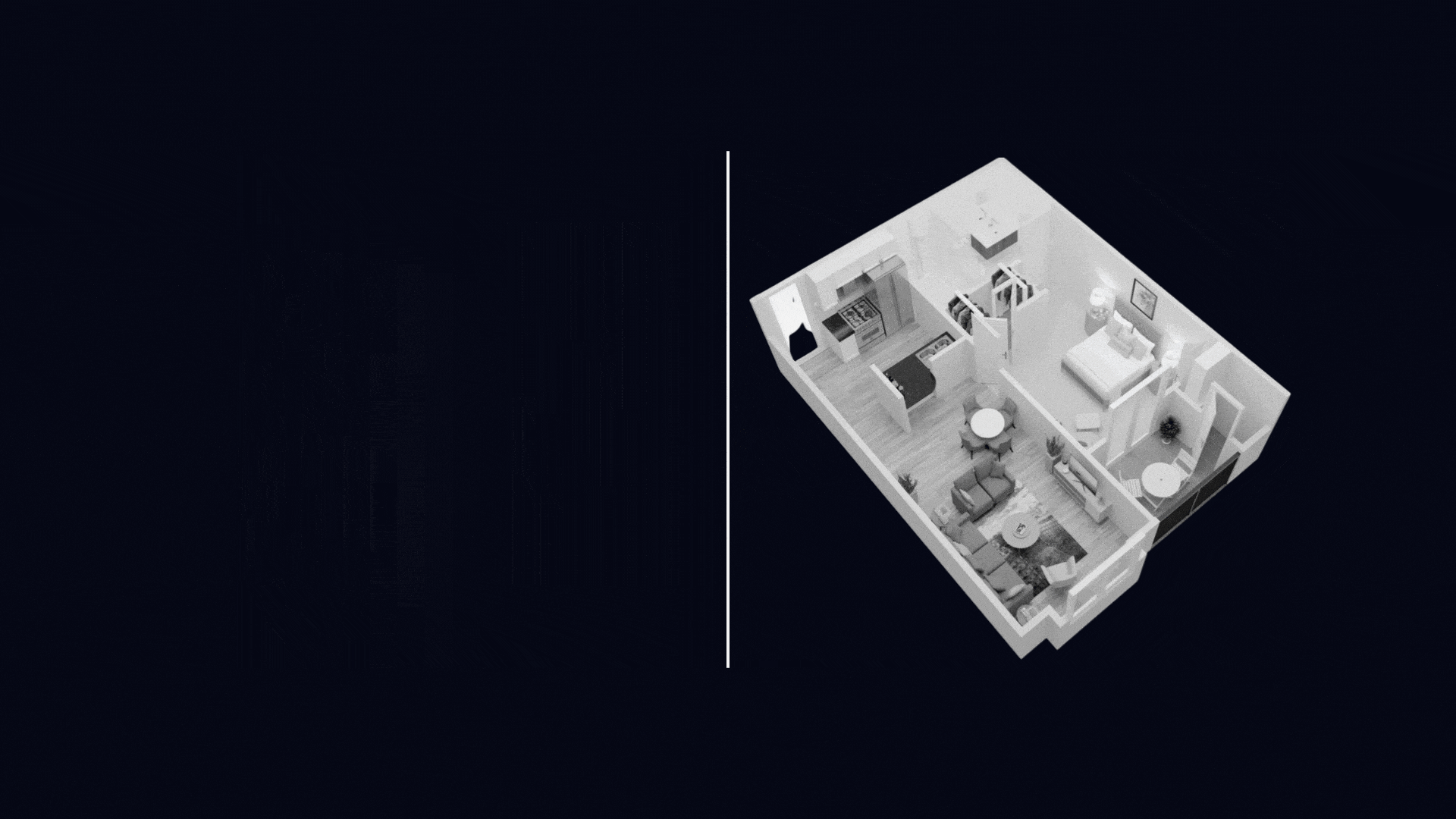
Converts raw image into editable floor plans, explore renovation ideas, and seamlessly turn concepts into reality
LLM solutions are still broken for most enterprises. Neuramonks fixes that. We design, build, and deploy large language model systems that connect to your real business data and run reliably in production from day one.



We've engineered features that will actually
make a difference to your business.
We build LLM-powered recommendation engines that understand intent and behaviour to surface the right products and boost conversions.
Scripted chatbots break the moment a user goes off script. Our conversational bots use an LLM with structured memory and fallback logic to handle multi-turn conversations, ambiguous queries, and escalation paths without the usual failure modes.
Most enterprise chatbots fail because they hallucinate or return stale answers. Our RAG-based knowledge bots connect your LLM to live internal documents, wikis, and databases so every answer is grounded in your actual data. Teams that deploy this stop losing hours to manual search.
Your analysts spend two days pulling data and formatting slides. We automate that. Our report generation system queries structured data sources, summarizes findings, and produces formatted output in your template, triggered on a schedule or on demand.
Semantic search built on LLM embeddings finds what users mean, not just what they typed. We replace legacy keyword search with a retrieval system that understands synonyms, context, and query intent, so users find the right result on the first try.
Contracts, invoices, and compliance documents need more than OCR to be useful. We combine OCR with LLM classification and entity extraction to turn unstructured documents into structured records that feed directly into your systems.
Research, legal review, and customer feedback generate more text than any team can read. Our summarization pipelines produce accurate, length-controlled summaries that preserve the important details and cut the noise.
Our generative AI systems speed up content production and software development. From first-draft copy and technical documentation to boilerplate code and test coverage, we build generation pipelines that fit into your existing tools.
Survey responses and support tickets tell you what happened. Sentiment analysis tells you how people felt about it. We build LLM-based classifiers that go beyond positive or negative to catch frustration signals and churn indicators at scale.
Generic translation APIs lose domain terminology and brand tone. We fine-tune translation pipelines on your content so technical terms, regulatory language, and voice survive the conversion across every language you support.
When standard AI models don't meet your accuracy needs, we fine-tune them using your domain data. From data preparation and training to evaluation and deployment, we deliver business-ready AI without the need for an in-house ML team.
We build LLM-powered recommendation engines that understand intent and behaviour to surface the right products and boost conversions.
Scripted chatbots break the moment a user goes off script. Our conversational bots use an LLM with structured memory and fallback logic to handle multi-turn conversations, ambiguous queries, and escalation paths without the usual failure modes.
Most enterprise chatbots fail because they hallucinate or return stale answers. Our RAG-based knowledge bots connect your LLM to live internal documents, wikis, and databases so every answer is grounded in your actual data. Teams that deploy this stop losing hours to manual search.
Your analysts spend two days pulling data and formatting slides. We automate that. Our report generation system queries structured data sources, summarizes findings, and produces formatted output in your template, triggered on a schedule or on demand.
Semantic search built on LLM embeddings finds what users mean, not just what they typed. We replace legacy keyword search with a retrieval system that understands synonyms, context, and query intent, so users find the right result on the first try.
Contracts, invoices, and compliance documents need more than OCR to be useful. We combine OCR with LLM classification and entity extraction to turn unstructured documents into structured records that feed directly into your systems.
Research, legal review, and customer feedback generate more text than any team can read. Our summarization pipelines produce accurate, length-controlled summaries that preserve the important details and cut the noise.
Our generative AI systems speed up content production and software development. From first-draft copy and technical documentation to boilerplate code and test coverage, we build generation pipelines that fit into your existing tools.
Text Queries Processed
AI Response Accuracy
Custom LLM Models Deployed
Words Generated

Trusted by
.webp)

.webp)

Claude AI

LangChain & LlamaIndex

Whisper (Speech-to-Text AI)
.webp)
T5 (Text-to-Text Transfer Transformer)

BERT & RoBERTa

Mistral A
.webp)
RAG (Retrieval-Augmented Generation)
.webp)
Llama (Meta AI)

Falcon LLM

GPT-4 / GPT-3.5

We deliver Enterprise AI Solutions designed for real-world performance — secure, scalable, and aligned with operational and revenue objectives.

Our AI solutions support Healthcare, Manufacturing, E-commerce, Construction, and the Diamond Merchant industry, enabling data-driven decisions, operational efficiency, intelligent automation, and enhanced customer experiences.
As a custom AI Solutions company, we've engineered features that will actually make a difference to your business.

Dive into videos with dynamic, interactive segments—explore, customize, and engage with content tailored just for you.
Interactive Navigation
Explore content freely.
Customizable Experience
Tailor your viewing.
Engaging Storytelling
Craft unique narratives.

Streamlined COVID Testing with Secure Results Management for Safer Travel.

AI-Powered Font Recognition
Instantly identify fonts from any image using deep learning models trained on 3 lakh+ styles.
Scalable Matching Engine
Recognize new fonts on the fly without retraining—built for growth and flexibility.
Design-Centric Integration
Deliver accurate results with designer-grade precision and seamless UI integration.

Create standout resumes with ATS Scoring, match them to jobs, and manage updates with ease.
AI Product Advisor
Recommends gear from 30,000+ products based on user intent and context.
Domain-Trained Chatbot
Answers questions like a fishing expert using industry-specific LLM training.
Sales-Driven Suggestions
Improves product discovery and shortens decision cycles for all user types.











































.webp)

.webp)

















.webp)





See how our AI and ML solutions have transformed businesses, straight from our clients' experiences.
Schedule a complimentary consultation with our Custom Agentic AI development specialists. Investigate how intelligent agents can optimise your operations, reduce costs, and accelerate business velocity.

Still got questions? Feel free to reach out to our incredible
support team, 7 days a week.
How do LLM AI agents work in business automation?
LLM AI agents combine a large language model with a set of tools and a decision loop. The model reads a task, decides which tool to call, processes the result, and takes the next step. In business automation this means an agent can draft a report, query a database, send a notification, and escalate edge cases without a human in the loop. Neuramonks builds agents that integrate with the systems your team already uses, with clear guardrails on what the agent can and cannot do.
Are your LLM services secure and enterprise-ready?
Absolutely. Our LLM services are built with enterprise-grade security, governance, and deployment flexibility to support regulated and high-scale environments.
What are the challenges of deploying LLM solutions in enterprise?
The four problems that come up most often are hallucination on domain-specific queries, latency that makes the tool unusable in production, cost that scales badly under real traffic, and access control when the system touches sensitive internal data. Most of these are architecture problems, not model problems. The right LLM solution architecture uses retrieval, caching, role-based access, and smart routing to handle each one before you hit production.
What is RAG and how does it improve LLM accuracy?
RAG stands for retrieval augmented generation. Instead of relying on what the model memorized during training, the system retrieves relevant chunks from your documents or database at query time and feeds them into the prompt as context. The model answers based on that retrieved content, not guesswork. This removes hallucination on domain topics and keeps answers current without retraining. For enterprises with large internal knowledge bases, RAG is usually the fastest path to a working LLM deployment.
How do I build a custom LLM for my company?
Most companies do not need to train a model from scratch. The practical path is to start with a base model, fine-tune it on your labeled data, then combine it with RAG for domain retrieval and a wrapper for your infrastructure. Full pretraining only makes sense for highly specialized domains with large proprietary datasets. We map your actual use case against what fine-tuning versus RAG versus prompting can solve and recommend the approach with the best cost-to-accuracy ratio for your requirements.
What should I look for when hiring an LLM services provider?
Look for a team that explains tradeoffs between models, not just implements whichever one is trending. Ask how they handle evaluation provider without an answer is building without feedback. Check whether they have production deployments, not just demos. Confirm they understand your data privacy requirements before any model sees your data. And make sure they can describe their LLM solution architecture in plain terms. If they cannot, the architecture probably does not exist yet.
How much does it cost to implement an LLM solution?
Cost depends on three variables: model choice, usage volume, and integration complexity. A RAG-based internal tool using a hosted API typically runs lower than a fully custom build with fine-tuning and on-premise deployment. Ongoing costs split between inference tokens and infrastructure. We give every client a cost model with realistic projections at low, medium, and high usage before the build starts. Talk to our team and we will scope it in the first conversation.
Free, No Commitment
Share your vision. Our senior AI architects will map it into a concrete technical plan, delivered to your inbox within 24 hours.
Response within 24 hours, guaranteed
100% NDA-protected & confidential
200+ AI Models in Production
48+ AI & Cloud Specialists
100+ clients already scaled with us




