
TABLE OF CONTENT
Direct answer: Deploying production-grade agentic workflows using n8n automation and Gemini requires connecting a self-hosted n8n instance to the Gemini API via authenticated HTTP nodes, structuring agent loops with conditional branching, adding memory via vector stores, and enforcing observability through structured logging enabling reliable, scalable AI solutions for enterprise environments.
The promise of AI agents systems that can reason, take actions, and adapt in real time has moved well beyond demos and prototypes. Enterprise teams are now demanding production deployments: workflows that handle thousands of events per day, gracefully recover from errors, maintain context across sessions, and integrate with existing business systems without ripping them apart.
The combination of n8n automation (self-hosted, open-source workflow orchestration) and Google Gemini (a frontier multimodal LLM with long context windows) has emerged as one of the most compelling stacks for exactly this challenge. Together, they give engineering teams control over code and the intelligence of a top-tier language model without relying on a single SaaS vendor for everything.
This guide is written for senior engineers and technical leads who need to move fast without creating technical debt. We'll cover architecture decisions, real implementation steps, and the operational practices that separate a proof-of-concept from a system your organization can bet on.
RELATED READ
n8n vs Zapier vs Make for AI Automation Which One Actually Scales in 2026? A deep comparison of the top automation platforms for enterprise AI workloads, with benchmarks and migration guidance
Why the n8n + Gemini stack works for enterprise
Most enterprise automation projects fail not because of missing features, but because of architectural mismatch. Tools built for marketing teams end up running critical operational pipelines. The n8n and Gemini stack avoids this by giving you full ownership of both the orchestration layer and the intelligence layer.
n8n is self-hosted, meaning your data never leaves your infrastructure unless you explicitly send it somewhere. Gemini, accessed via the Google AI API or Vertex AI, gives you a model capable of processing 1 million token context windows enough to reason over full contract documents, multi-day conversation threads, or entire codebases in a single call. The combination means your agent can be given large, complex tasks without hitting the token ceilings that cripple other setups.
For teams already working with an AI automation agency like Neuramonks or evaluating vendors for implementation support, this stack also reduces lock-in risk. The workflow definitions in n8n are portable JSON, and the Gemini API conforms to standard REST patterns that can be swapped for other providers if needed.
Architecture principle: In agentic systems, the orchestration layer (n8n) handles state, routing, and integrations. The LLM layer (Gemini) handles reasoning, summarization, and decision generation. Keep these responsibilities clean don't put business logic inside prompts.
The anatomy of a production agentic workflow
Before writing a single node, you need to understand what makes an agentic workflow different from a standard automation. A standard workflow is deterministic: trigger → do X → do Y → done. An agentic workflow is iterative: trigger → reason → act → observe → reason again. This loop is what gives the system its power and its risk.
In n8n, this loop is expressed through a combination of HTTP request nodes (calling Gemini), Function nodes (evaluating the response and deciding the next step), conditional branches (routing based on the agent's output), and loop-back connections (allowing the agent to iterate until a stopping condition is met).
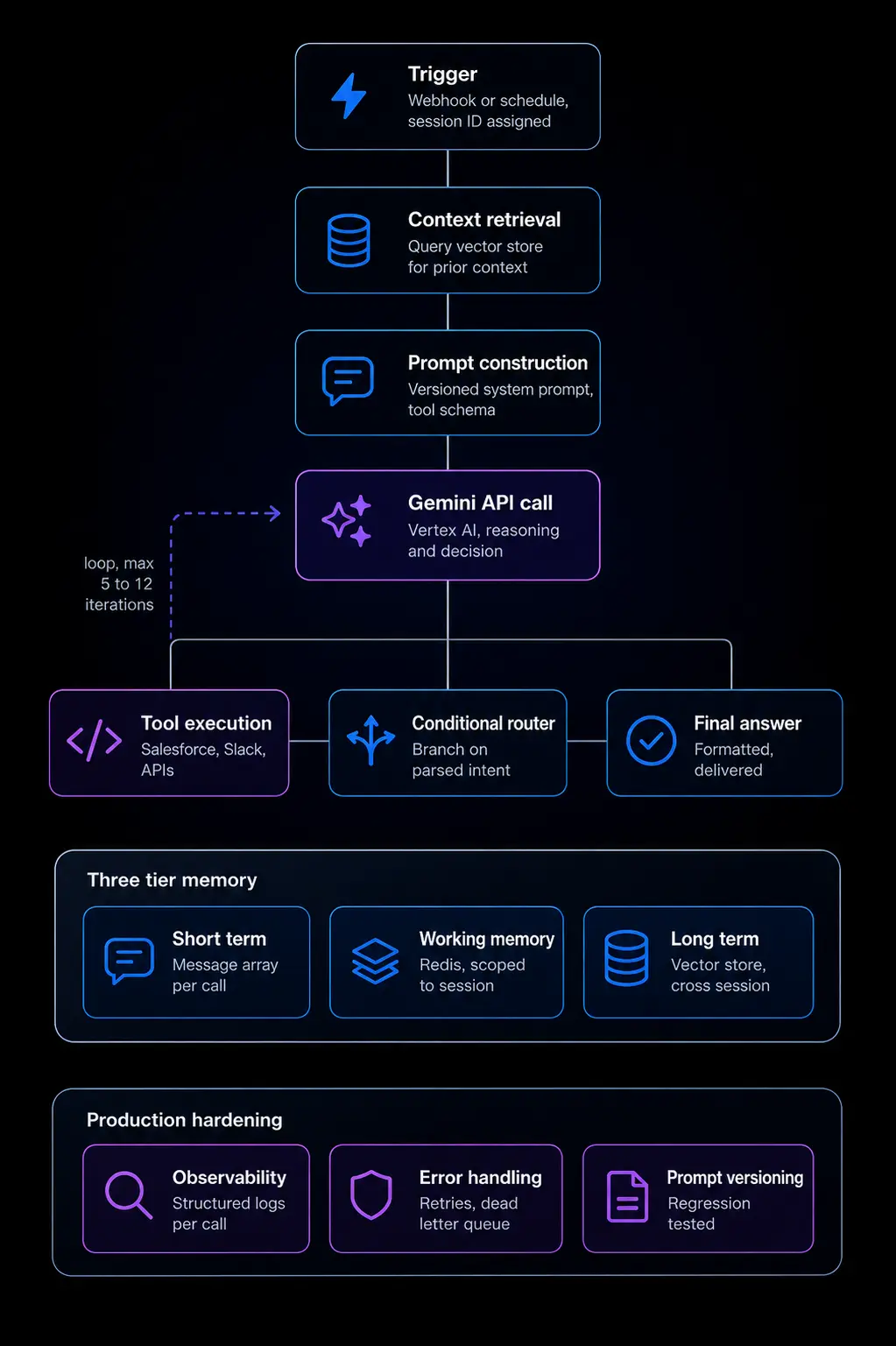
Step-by-step implementation guide for setting up for n8n Enterprise
The following walkthrough covers the decisions and configurations you'll encounter when building this in a real enterprise environment. These aren't simplified tutorial steps — they reflect what actually matters when the system needs to handle production traffic.
1. Infrastructure Hardening & High Availability
For true enterprise deployments, avoid single-node configurations or n8n Cloud for sensitive workloads. Instead, host a scalable n8n instance within your own Virtual Private Cloud (VPC) using a Kubernetes-managed container deployment.
- Execution Scaling (Queue Mode): Enforce EXECUTIONS_MODE=queue in your environment variables. Deploy an enterprise-grade Redis cluster to act as the message broker. This allows a separate fleet of stateless n8n worker nodes to scale horizontally and absorb heavy agent loops without compromising the responsiveness of your main n8n instance.
- Database Optimization: Run n8n on a managed PostgreSQL database. Because agentic loops write enormous amounts of step-by-step telemetry, you must set EXECUTIONS_DATA_PRUNE=true alongside a strict EXECUTIONS_DATA_MAX_AGE policy to prevent storage bloat.
- Secrets Management: Do not store third-party API tokens inside n8n workflow configurations. Utilize n8n Enterprise's native external secrets integration to stream credentials out of HashiCorp Vault or AWS Secrets Manager at runtime.
2. Enterprise Authentication: Gemini via Vertex AI / Agent Platform
While Google AI Studio works well for prototyping, enterprise compliance teams demand the security posture of Google Cloud's Gemini Enterprise Agent Platform (formerly Vertex AI). It provides strict data isolation, VPC Service Controls, and robust audit logging.
- IAM Scopes: Configure an n8n Credentials block using a Google Service Account JSON key that is explicitly limited to the Gemini Enterprise Agent Platform User (formerly Vertex AI User) or GenAI Administrator role.
- Targeting the REST Endpoint: Set your n8n HTTP Request node to a POST request pointing to Google's regionalized production endpoint template:
- $$\text{https://\{REGION\}[-aiplatform.googleapis.com/v1/projects/](https://-aiplatform.googleapis.com/v1/projects/)\{PROJECT-ID\}/locations/\{REGION\}/publishers/google/models/\{MODEL-ID\}:generateContent}$$
- Data Residency: Ensure that the {REGION} parameters align perfectly with your company's localized compliance frameworks (such as us-central1 for domestic data handling or europe-west3 for strict GDPR adherence).
3. Structuring the Agent Loop with n8n Nodes
The execution loop must remain resilient, clean, and bounded. Build your architecture using these precise functional steps:
- Trigger & Context Initialization: When a webhook or schedule fires, write a unique sessionId to your fast-access storage layer (like Redis or Supabase) to initialize state.
- Context Retrieval (Vector Store Integration): Query your enterprise vector database (Qdrant, Pinecone, or PGVector) using native n8n Vector Store components to feed highly specific operational context to the agent before it calls the LLM.
- The Reasoning Call (HTTP Request): Construct a structured JSON message array containing system rules, active tools schemas, retrieved context, and the user's explicit objective. Hardcode Gemini's request parameters to return a deterministic json_object.
- The Switch/Router Node: Evaluate the returned structure using an explicit n8n Switch node. If the payload indicates a tool_call, dynamically branch out to execute an integration. If it outputs a final_answer, bypass the loop and send the completion path.
- Loop Controller & Safety Braking: Use an evaluation Code node to increment an execution counter stored inside the workflow variables. Enforce a strict ceiling (e.g., 8–12 iterations max). If a loop enters an unexpected hallucination cycle and hits this ceiling, route the payload immediately to a human-in-the-loop dead-letter queue.
4. Memory Architecture for Stateful Agents
Stateless agents are almost useless in enterprise contexts. Users expect continuity. The standard pattern is a three-tier memory system:
- Short-Term Memory: The live message array passed back and forth within an active execution branch.
- Working Memory: A shared Redis key tied to the specific sessionId that tracks variable tool outcomes during the active cycle.
- Long-Term Memory: A vector store configuration that indexes compressed summaries of past sessions to keep cross-interaction intelligence alive.
Production hardening: what separates pilots from platforms
The jump from a working prototype to a production system that your business can rely on requires deliberate hardening in four areas.
Observability and structured logging
Every Gemini API call should emit a structured log entry: timestamp, session ID, input token count, output token count, latency, and the reasoning step number. Use n8n's Code node to write these to a centralized log aggregator (Datadog, Grafana Loki, or even a simple Postgres table). Token costs compound quickly in agentic loops — you need per-session visibility to catch runaway workflows before your API bill does.
Error handling and graceful degradation
Gemini API calls will occasionally fail: rate limits, temporary outages, malformed responses. Your n8n workflow needs explicit error branches with exponential backoff on retries, a dead-letter queue for tasks that exceed max retries, and a fallback response path that notifies the end-user rather than silently failing. The Error Trigger node in n8n combined with a notification node (Slack or email) is the minimum viable observability layer.
Prompt versioning and regression testing
System prompts are code. Treat them as such. Store prompt templates in a version-controlled repository, reference them in your n8n workflow by version ID, and run a regression suite before promoting any prompt changes to production. A prompt that works in testing can subtly change agent behavior in ways that only manifest under production traffic patterns — systematic testing catches this early.
Stop Planning AI.
Start Profiting From It.
Every day without intelligent automation costs you revenue, market share, and momentum. Get a custom AI roadmap with clear value projections and measurable returns for your business.

Enterprise Use Cases for the n8n + Gemini Stack
Deploying an agentic workflow is highly impactful when applied to industry-specific operational bottlenecks. Because n8n handles deep system integrations and Gemini processes massive, unstructured datasets, enterprises can automate complex, decision heavy workflows that traditional automation tools cannot touch.
1. Manufacturing: Autonomous Supply Chain Remediation
- The Orchestration (n8n): Monitors live factory IoT logs, enterprise asset systems (SAP, Oracle), and inbound vendor delivery emails.
- The Intelligence (Gemini): Ingests an unstructured carrier delay alert and uses its multimodal intelligence to inspect attached customs document scans or freight bills. It evaluates the raw text data against strict legal supply manuals stored in the vector layer.
- The Action: The agent autonomously references live material balances in the ERP. If parts are short, it automatically targets alternative pre-approved suppliers, generates a drafted RFQ (Request for Quote), modifies the schedule in the manufacturing execution system, and routes an actionable summary to the logistics manager for approval.
2. Construction: Real-Time RFI & Compliance Tracking
Construction AI solutions have evolved from static document logs into dynamic knowledge engines that eliminate critical administrative delays on-site. By pairing n8n's visual node structures with Gemini's high context limitations, firms can process complex requests for information (RFIs) proactively rather than reactively.
- The Orchestration (n8n): Syncs field management tools (like Procore or Autodesk Build) directly with internal document servers and city zoning databases.
- The Intelligence (Gemini): When an engineer uploads an urgent Request for Information (RFI) regarding a spatial blueprint conflict, Gemini processes the message alongside massive blueprint architectural files (leveraging its huge context capacity). It runs comparisons against municipal building codes to determine compliance.
- The Action: The agent drafts an objective, technically sound design recommendation, pushes structural updates back into the central BIM logs, and fires an alert to the compliance safety officer if the variation requires a municipal variance request.
3. Healthcare: Automated Prior Authorization Triaging
Advanced Healthcare AI solutions target the immense administrative strain of insurance navigation, cutting authorization turnaround loops from weeks to minutes. Under strict federal data exchange rules, this stack replaces multi-hour manual data re-entry with precise, secure automation.
Compliance Note: This use case relies completely on a self-hosted n8n installation run entirely inside a protected, HIPAA-compliant private cloud environment utilizing enterprise-hardened data isolation boundaries.
- The Orchestration (n8n): Interfaces directly with Electronic Health Record (EHR) environments via secure HL7/FHIR webhooks to ingest raw practitioner voice logs or insurance exception files.
- The Intelligence (Gemini): Translates complex medical vocabulary found inside clinician notes and tests, comparing the clinical justification directly against thousands of pages of insurance policy guidelines.
- The Action: Automatically structures, populates, and delivers complete medical authorization records directly into health portal APIs. If an invalid automated rejection occurs, it hands the case directly over to specialized hospital billing staff along with a clear brief outlining why the rejection breached regular policy limits.
CASE STUDY NEURAMONKS
Custom Gemini LLM integration via Dify plugin development
Neuramonks, a leading Dify AI Development Company, built a custom Gemini provider plugin for the Dify AI platform — enabling enterprise clients to route their agentic workflows through a fully approved, org-level Gemini LLM integration. The plugin bypassed Dify's default model limitations by implementing the Approved Provider protocol, giving clients control over model selection, API keys, and token budgets within the same visual workflow environment.
Read the full case study
Scaling the stack: from single workflow to multi-agent system
Once a single agentic workflow is stable, the natural next step is multi-agent architectures systems where specialized agents collaborate on complex tasks. In n8n automation, this is implemented through a coordinator-worker pattern: a top-level orchestrator workflow receives tasks, decomposes them, and triggers child workflows via n8n's Execute Workflow node. Each child workflow is a specialized agent (one for document analysis, one for database queries, one for external API calls) with its own Gemini context and memory scope.
This is where Neuramonks consistently delivers differentiated value for enterprise clients not just connecting nodes, but designing the agent topology that matches the client's operational complexity. A single generic agent cannot reliably handle the breadth of tasks a real business generates. Specialized agents with clear boundaries and well-defined handoff protocols consistently outperform monolithic prompts trying to do everything.
As a Dify AI Development Company, Neuramonks also builds parallel implementations using Dify's visual agent builder for teams that prefer a lower-code interface for managing agent chains often combining Dify for agent logic with n8n for the integration layer, giving clients the best of both environments.
Security considerations for enterprise deployments
Agentic systems that can take actions writing to databases, sending emails, calling external APIs require a security model that goes beyond standard web app practices. The principle of least privilege applies at the agent level: each tool available to the agent should have the minimum permissions needed to accomplish its specific task. A document summarization agent does not need write access to your CRM.
In n8n, enforce this by creating separate credentials for each integration, scoped to the permissions that specific workflow actually needs. Audit credential usage quarterly. Log every tool call the agent makes with the session ID and user context that authorized it. For regulated industries (healthcare, finance), consider adding a human-in-the-loop node before any irreversible action n8n's Wait node combined with an approval webhook makes this straightforward to implement.
The Neuramonks' approach to enterprise AI automation
At Neuramonks, our implementation methodology for enterprise agentic systems starts with a capability audit mapping existing workflows, data sources, and integration points before writing a single node. The most common mistake we see is teams starting with the technology (n8n, Gemini, Dify) before clearly defining which decisions the agent needs to make, which data it needs access to, and which actions it should never take autonomously.
The second phase is a controlled pilot: a single, high-value workflow deployed to a subset of users with full observability instrumentation. This generates the real usage data needed to tune prompts, adjust memory strategies, and right-size the agent's tool set before organization wide rollout. Enterprise deployments that skip this phase consistently encounter production incidents that could have been caught in a three-week pilot.
Start your enterprise AI automation journey
Whether you're architecting your first agentic workflow or scaling an existing system, Neuramonks brings the engineering depth and implementation experience to get it right in production not just in demos.
Get in touch with Neuramonks

Ketan Kanjiya
Ketan Kanjiya is a Machine Learning researcher and Chief Research Officer at Neuramonks, an AI-focused technology company based in Ahmedabad, Gujarat. With hands-on expertise in AI/ML, image processing, and web application development, he has led research initiatives across F(x) Data Labs and Kshatrainfotech. Ketan writes to simplify advanced technical concepts for developers and tech enthusiasts alike.






