TABLE OF CONTENT
There's a peculiar irony at the heart of modern AI: the most powerful models are often the least useful for everyday business problems. While the industry has chased scale — hundreds of billions of parameters, trained on everything the internet has ever produced — a quieter revolution has been unfolding in enterprise deployments.
That revolution is the rise of the Small Language Model. The prevailing narrative — that bigger models inevitably deliver more business value — is being dismantled, use case by use case, by companies disciplined enough to ask a simpler question: does the size of this model actually match the size of the problem?
For the overwhelming majority of enterprise AI applications, the answer is no. Smaller, purpose-built models don't just reduce costs — they deliver better outcomes. Understanding why is one of the most strategically important questions a business leader can engage with in 2026.
The Scale Myth — Why Bigger Does Not Always Mean Better
When frontier AI models burst onto the enterprise scene, the implicit promise was straightforward: more parameters, more intelligence, more value. That logic made intuitive sense and it drove enormous investment in general-purpose AI infrastructure. The problem emerged when organisations moved from proof-of-concept into production and discovered that the benchmarks and the boardroom presentations had not prepared them for what running a massive general-purpose LLM at scale actually costs — financially, operationally, and in terms of the accuracy gaps that surface when you ask a model designed to know everything to be reliably precise about something very specific.
The core problem: general-purpose models optimise for breadth. Business problems demand depth. That mismatch is costing enterprises millions in wasted compute, unreliable outputs, and AI deployments that never make it past the pilot stage.
A large general-purpose model is like hiring a brilliant generalist who can discuss almost any topic with apparent fluency but has genuine expertise in none of them. When a logistics company needs a model that understands freight classification codes, carrier penalty structures, and customs documentation formats, that generalism is not an asset — it is a source of errors that somebody on the operations team has to catch and correct. When a financial institution needs consistent, auditable outputs on regulatory classification tasks, the variability that comes with a model trained to be creative and broad becomes a compliance liability.
SLMs are built on the opposite philosophy. Rather than trying to know everything, they are trained to know exactly what a specific domain requires — and to know it with the precision and consistency that production-grade business processes demand. The result is a model that is faster, cheaper to run, more accurate on the target task, and far more predictable in the kinds of ways that actually matter when AI is embedded into core operations.
Stop Planning AI.
Start Profiting From It.
Every day without intelligent automation costs you revenue, market share, and momentum. Get a custom AI roadmap with clear value projections and measurable returns for your business.

What Actually Separates SLMs from LLMs
The difference isn't purely parameter count — though modern SLMs do run far smaller than the hundred-billion-plus scale systems that dominate headlines. The more consequential gap is in training philosophy and purpose.
A well-designed SLM is built on a curated, domain-specific corpus: a legal SLM trained on case law and contracts understands legal nuance that general models can't match; a supply chain SLM trained on logistics data classifies freight with a consistency that broad models simply don't achieve.
The result isn't just adequate performance — it's excellent, predictable performance on the specific tasks businesses need done reliably, at volume, every day. That predictability also makes compliance monitoring and operational governance far simpler than managing the variable outputs of a larger, less focused system.
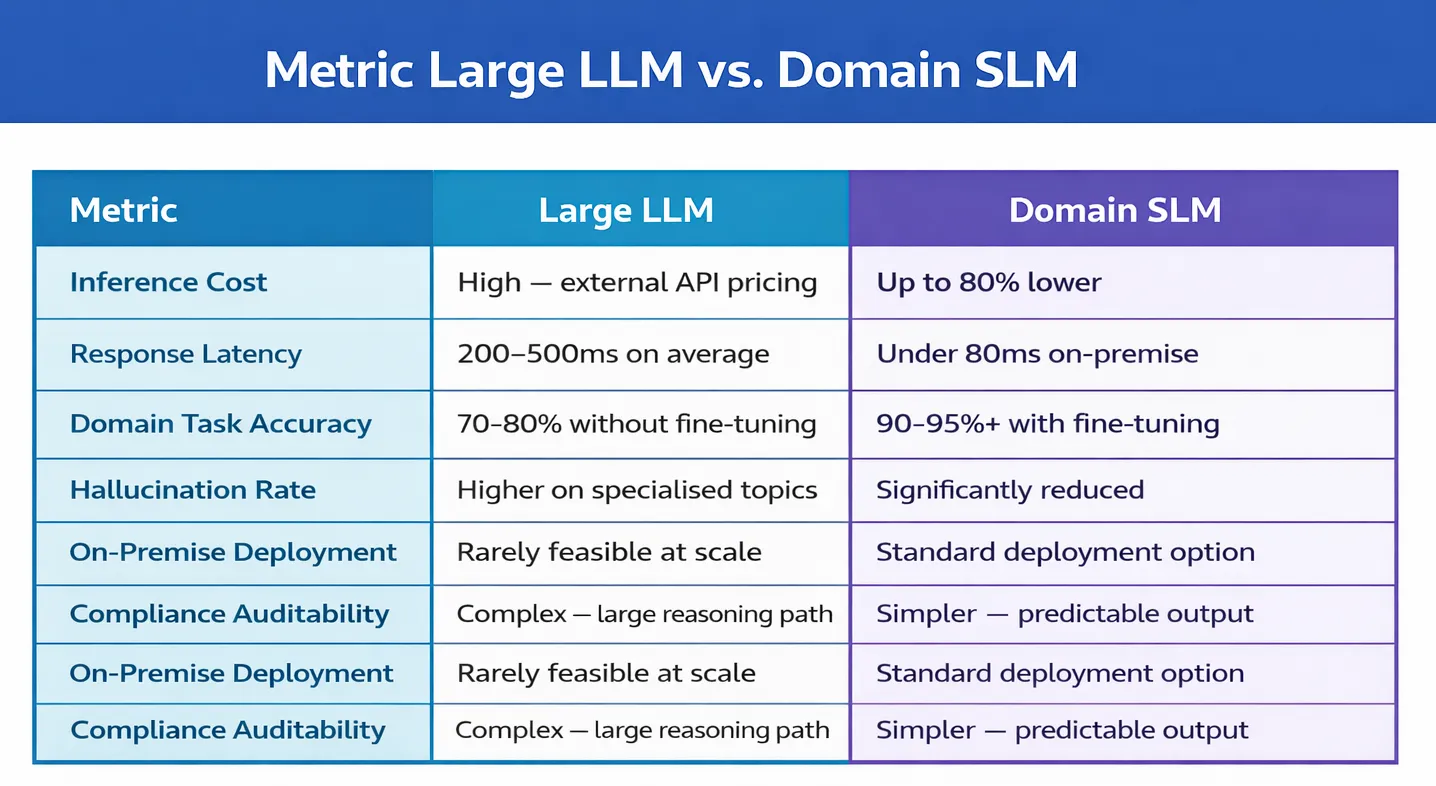
SLM vs LLM — Head-to-Head on What Actually Matters
Industry Applications: Where SLMs Are Already Winning
The practical impact of SLMs becomes most tangible when mapped against the specific industries and workflows where they are already outperforming larger, more expensive alternatives. Three sectors in particular illustrate why domain-focused models have become a genuine strategic advantage for organisations willing to move beyond the default assumption that bigger is better.
AI in Healthcare: Accuracy Where It Cannot Be Negotiated
The application of AI in healthcare settings places uniquely demanding requirements on any model that enters the workflow. Clinical terminology is highly specialised, diagnostic codes are precise, and the consequences of an error — a miscoded procedure, a misread clinical note, a misfiled patient summary — extend well beyond operational inconvenience into patient safety and regulatory risk. General-purpose models frequently stumble on medical vocabulary or produce outputs that require extensive expert review before any clinical action can be taken, which largely defeats the efficiency case for deploying AI at all.
SLMs trained on verified medical literature, clinical notes, electronic health record structures, and diagnostic protocols behave fundamentally differently. They understand the vocabulary precisely, format outputs in the structures that clinical workflows actually require, and fail in ways that are predictable and catchable rather than subtly plausible but wrong. Their smaller footprint also makes on-premise deployment feasible — which resolves the data governance concerns that have held many healthcare organisations back from deploying AI into their most sensitive and valuable workflows.
Voice Agent Deployments: Where Latency Is the Product
A conversational voice agent handling customer service calls, appointment scheduling, or technical support queries operates under constraints that large general-purpose models structurally struggle to meet. Every additional 200 milliseconds of inference latency creates a noticeable pause that breaks the conversational rhythm and degrades the user experience in ways that are immediately and viscerally apparent to the person on the other end of the call. General-purpose models running through external APIs introduce exactly this kind of latency — network round trips plus the inherent inference overhead of a massive model combine to make real-time conversation feel mechanical and halting.
SLMs deployed on regional or edge infrastructure eliminate most of that latency. They respond in the time windows that natural conversation actually requires. They also produce more consistent, domain-appropriate outputs for the specific query types these systems are designed to handle — which means fewer unexpected responses, fewer escalations, and a far more reliable experience at volume. For organisations running conversational AI at scale, the difference between a large general model and a well-tuned SLM is often the difference between a product that customers tolerate and one they actually prefer.
Enterprise AI Automation: Economics That Actually Scale
The economics of AI Automation pipelines — the continuous, high-volume workflows that process thousands of documents, transactions, or decisions per hour — make the cost difference between SLMs and large general-purpose models particularly stark. At the inference volumes that serious automation requires, the per-call cost of a large frontier model compounds into annual infrastructure bills that can reach seven figures for a single automated workflow. This pricing structure makes many legitimate automation use cases economically unviable before they ever reach the deployment decision.
SLMs running on purpose-built infrastructure change the calculation entirely. Inference costs drop by 60–80%. Latency drops in parallel. And because the model is trained specifically for the task at hand, the accuracy is higher, the outputs are more consistent, and the human review overhead that erodes the ROI of general-purpose automation is dramatically reduced. Workflows that were previously too expensive to automate become straightforward business cases. The ceiling on how deeply AI can be woven into operations rises substantially — not because the AI became more powerful, but because it became more affordable to deploy at real operational scale.
The NeuronMonks Approach: Right Model for the Right Job
NeuronMonks, operating as a dedicated AI development company focused on enterprise deployments, has built its entire client methodology around a conviction that runs counter to much of the AI industry's default positioning: the best model is not the most powerful model — it is the most appropriate model. Every engagement begins not with a model selection decision but with a structured analysis of the actual task requirements, domain vocabulary, accuracy thresholds, latency constraints, privacy requirements, and volume expectations that the deployment must meet.
This discipline — refusing to reach for the biggest available model by default, and instead matching model complexity to task requirements — consistently produces better outcomes than the alternative. Clients who have previously deployed large general-purpose systems for high-volume, domain-specific tasks routinely discover that a purpose-built SLM delivers higher accuracy on their actual workflows, at a fraction of the infrastructure cost, with significantly less engineering overhead required to maintain reliable production behaviour over time.
The strategic insight that we brings to these engagements is deceptively simple: most enterprise AI problems are narrower than they appear, and narrow problems are exactly what smaller, focused models are designed to solve. The organisations that recognise this distinction — and build the architectural maturity to act on it — consistently outperform those that treat AI deployment as a question of which model is most impressive, rather than which model is most fit for the specific purpose at hand.
A Practical Framework for Choosing Between SLM and LLM
The SLM vs. LLM decision isn't a capability question — it's a fit question. Which model is right for this task, at this volume, within these latency, cost, and compliance constraints?
For domain-specific, high-volume workflows — document classification, clinical summarisation, compliance checking, entity extraction — SLMs win on every relevant dimension. The vocabulary is specialised, outputs are well-defined, and at scale, cost per inference genuinely matters. This describes the majority of core enterprise work.
For genuinely open-ended tasks — exploratory research, creative generation, unpredictable multi-domain queries — large LLMs remain the better choice. Most mature enterprise architectures are therefore hybrid: SLMs handling the bulk of operational work, larger models reserved for edge cases that actually require their breadth.
Right-Size Your AI, Right-Size Your Results
The organisations winning with AI in 2026 match model complexity to task requirements, route intelligently between model tiers, and treat deployment as a precision exercise — not a scale race. The case against using large models for everything isn't that they're bad. It's that for high-volume, accuracy-critical workflows, they're the wrong tool — and at enterprise scale, that's an expensive mistake that compounds every month.
In AI, as in engineering: fit beats force.
Explore Your SLM Options with NeuronMonks
Our specialists map your workflows, identify the highest-value SLM opportunities, and outline a deployment roadmap — no obligation, just clarity on where the gains are.