TABLE OF CONTENT
The market for AI solutions has split in two — and most companies haven't noticed yet. Something quietly shifted in 2025. The enterprise procurement teams that once defaulted to "just use OpenAI" started asking harder questions — about liability, about reasoning depth, about what happens when the model gives a compliance officer the wrong answer on a live call. By the time those conversations reached the C-suite, a pattern had already crystallised: Anthropic was winning 70% of new enterprise AI deals not by outperforming GPT on benchmark leaderboards, but by building something GPT never prioritised — a cultural identity rooted in precision, caution, and institutional trust.
Meanwhile, OpenAI was executing a different masterclass. Consumer integrations, plugin ecosystems, and ChatGPT as a daily habit for 200 million users. Two companies, two philosophies, two completely different winning conditions. Welcome to the specialisation era of AI — and if you're a CTO, founder, or product lead about to commit budget to an AI API, this breakdown will save you from a very expensive mismatch.
At NeuraMonks, we've embedded across enough enterprise architecture reviews and startup sprint cycles to have a real opinion on this. Here's what the tier list actually looks like in 2026 — and why the answer is rarely "one or the other."
Stop Planning AI.
Start Profiting From It.
Every day without intelligent automation costs you revenue, market share, and momentum. Get a custom AI roadmap with clear value projections and measurable returns for your business.

The Fork in the Road: Where Anthropic and OpenAI Diverged
The story of Claude vs GPT in the enterprise space isn't really about model intelligence anymore. Both are extraordinary. The fork happened at the philosophy level.
Anthropic built Claude with a constitutional AI framework — a set of embedded principles that govern how the model reasons, refuses, and handles ambiguity. For a risk officer at a bank, that's not a limitation, that's a feature. For a healthcare platform handling patient-facing workflows, predictable refusal behaviour is more valuable than raw output creativity.
OpenAI, by contrast, has been racing toward becoming the consumer super-app. The ChatGPT interface, voice mode, memory, operator instructions, marketplace plugins — it's a platform strategy, not just a model strategy. Extraordinary for developers building fast, for consumer products needing breadth, and for startups that need a capable general-purpose AI brain in their product by Friday.
Neither is wrong. They're just playing different games. The mistake enterprises make is evaluating them on the same criteria.
Head-to-head: Claude vs GPT at a glance
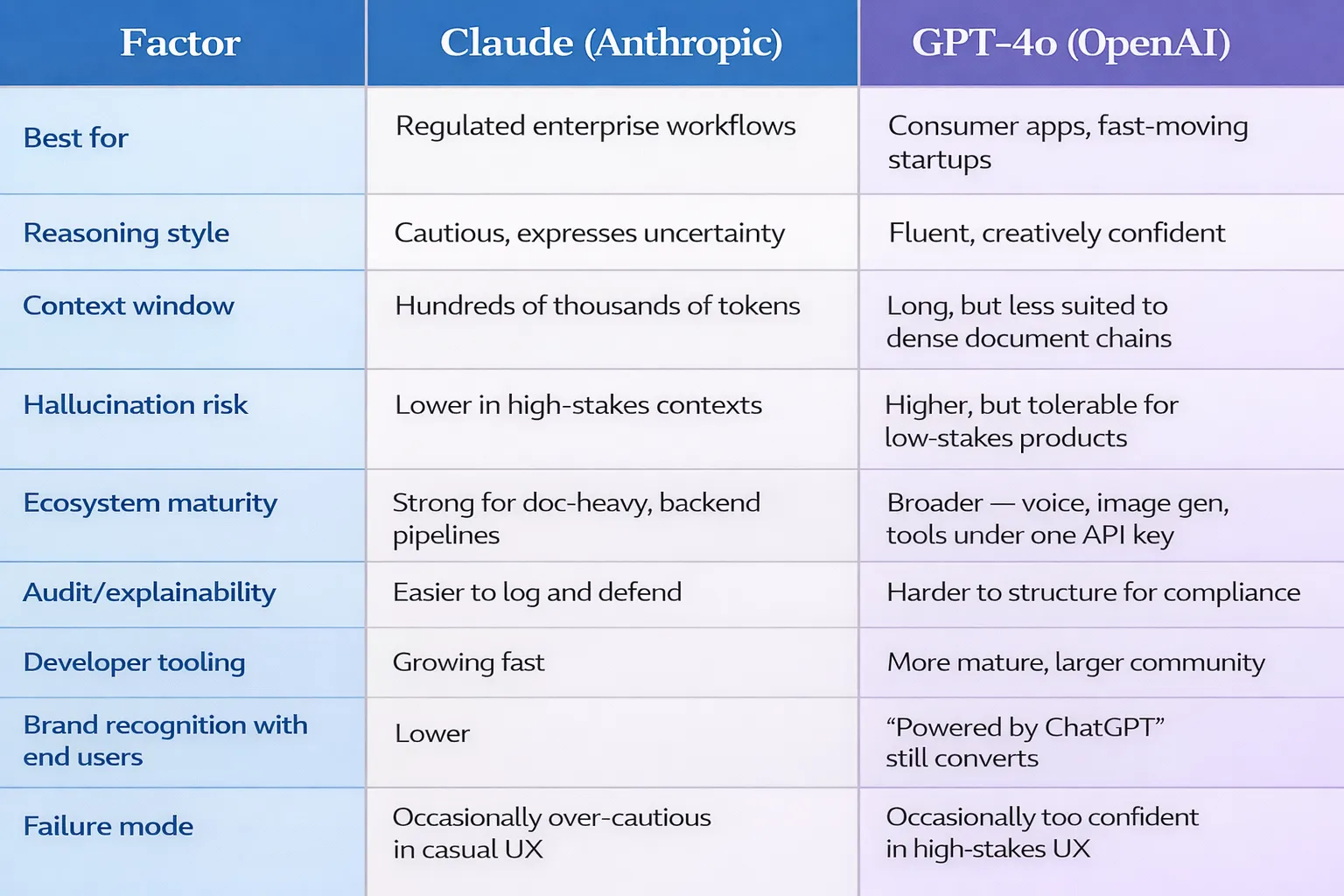
Why Enterprises Prefer Claude for Risk-Sensitive Workflows
When we audit enterprise AI pipelines — and this comes up in nearly every AI consulting services engagement — the pattern is consistent. The moment a workflow touches compliance, legal language, financial reporting, or patient data, the conversation shifts from "which model is smartest" to "which model can I defend in an audit."
Claude's architecture gives it a structural advantage here. Its responses are calibrated to express uncertainty when uncertainty exists. It doesn't hallucinate confidently — a trait that sounds minor until a model generates a fabricated legal citation that ends up in a client-facing document. Its longer context window (now extending to hundreds of thousands of tokens) allows enterprises to feed it entire regulatory documents, contract histories, or financial datasets without chunking — which means fewer stitching errors and more coherent outputs at scale.
The other enterprise-grade differentiator is agentic AI performance. When Claude is deployed inside multi-step automation pipelines — think: ingest a contract, extract obligations, flag anomalies, draft a risk summary, and route to the right department — it maintains chain-of-thought integrity across long tasks far better than most alternatives. This is critical for business-ready AI systems that can't afford mid-pipeline drift or context collapse.
The firms building AI tools for enterprises in regulated sectors — insurance, legal tech, healthcare SaaS, financial services — have largely converged on Claude as their foundation layer. The reputational calculus is simple: when something goes wrong with a consumer app, you patch and iterate. When something goes wrong with an enterprise compliance workflow, you face a very different kind of conversation.
The best AI model for business isn't the one that scores highest on MMLU. It's the one your legal team will sign off on deploying at scale.
Why GPT Dominates Consumer Apps & Startups
GPT-4o and its successors are still the default engine for a reason. If you're building a consumer-facing product where speed, creativity, multimodal input, and plug-and-play integrations matter more than auditability, GPT's ecosystem is hard to beat.
The OpenAI platform gives developers access to function calling, code interpreter, file search, image generation (DALL·E), and voice — all under one API key. For a startup moving at startup speed, that breadth eliminates vendor juggling. You don't need three different services; you ship with one.
Consumer applications have a different failure mode than enterprise ones. If a GPT-powered recipe assistant suggests a slightly unusual ingredient combination, the user laughs and tries again. The stakes are low. The feedback loop is fast. The product can iterate aggressively. That context rewards GPT's creative confidence and output fluency.
The developer tooling is also more mature. Extensive community documentation, open-source wrappers, and a marketplace of pre-built integrations mean that most GPT use cases have a published reference implementation somewhere. For resource-constrained startup teams, that ecosystem advantage is real money.
There's also the brand recognition factor. End users trust "powered by ChatGPT" in a way that they don't yet for newer AI brands. In B2C, trust is a conversion metric. That's not irrational — it's just the current market reality.
Use case fit: where each model belongs
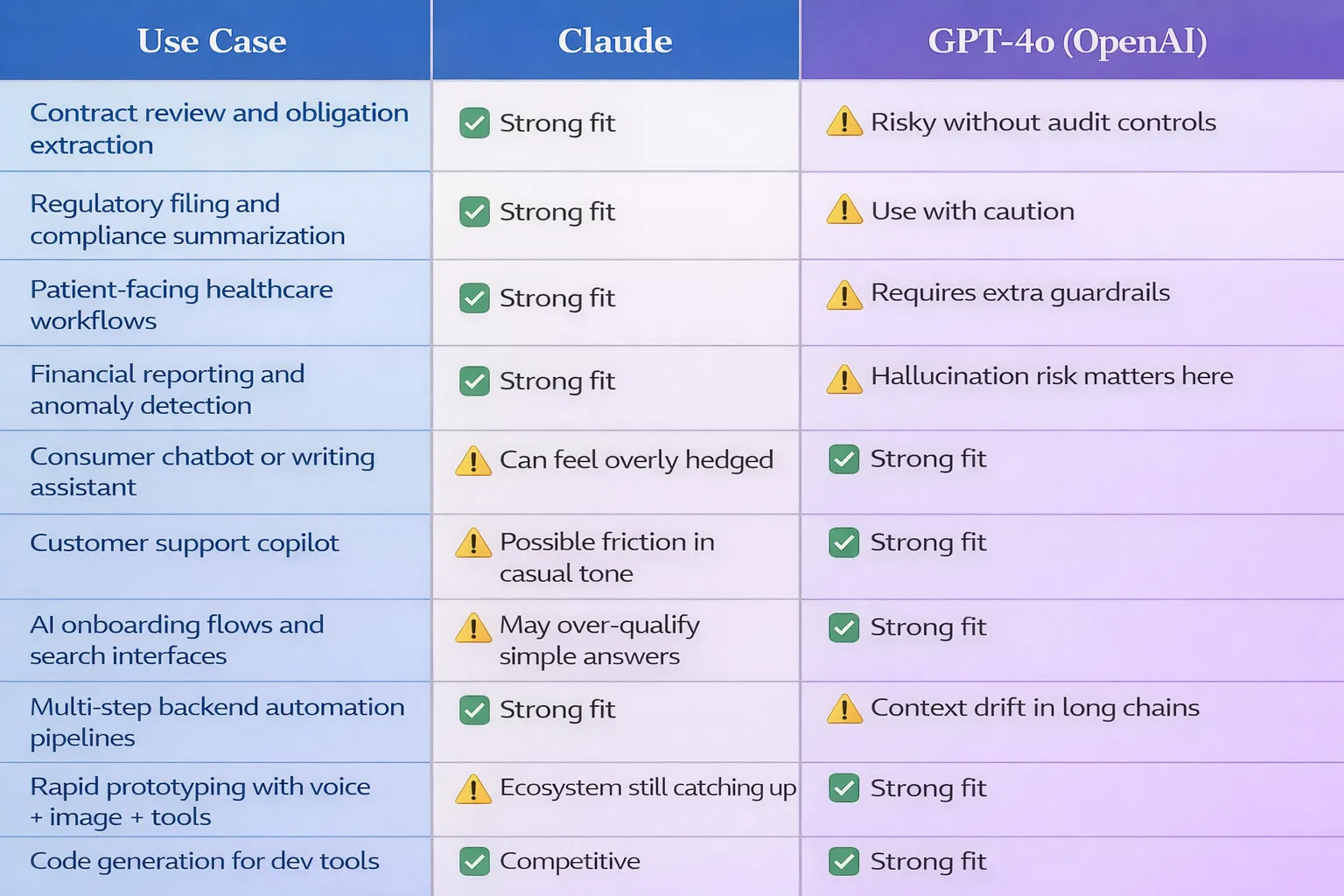
The Hidden Cost of Choosing Wrong
Here's what the benchmark comparisons don't show you: the cost of architectural mismatch six months into a build.
We've seen it at NeuraMonks — and this AI case study is more common than most teams admit. A Series B company built its entire enterprise compliance layer on GPT because it was the familiar choice. Twelve months later, they were re-platforming onto Claude because their enterprise clients required explainability logs and their current setup couldn't produce them reliably. The migration cost — in engineering hours, re-prompting, re-testing, and re-deploying — ran into six figures.
The inverse also happens. Teams building consumer features on Claude because it felt "safer," only to discover that Claude's deliberate caution creates friction in casual, fast-paced conversational contexts where users want snappy, opinionated responses, not hedged ones.
This is exactly why the AI solutions conversation needs to happen at the architecture stage — not after the first sprint is already done.
How to Actually Make the Decision: A Framework for CTOs
Rather than debating model quality in the abstract, here's the decision tree we use when consulting with engineering and product leaders:
- What is the failure mode of a wrong answer? — If a wrong answer creates a legal, financial, or reputational exposure, default toward Claude. If it creates a slightly awkward user experience, GPT's fluency is more valuable.
- What does your context window look like? — Long documents, regulatory corpora, and multi-session memory requirements favour Claude. Short, modular, single-turn interactions favour GPT's speed.
- Are you building a product or a pipeline? — Consumer-facing products with interface integrations trend toward GPT. Backend automation pipelines with multi-step logic trend toward Claude.
- Who reviews the outputs? — Human-reviewed workflows can absorb more model creativity. Fully automated outputs that go directly to end users or systems need tighter output discipline.
- What's your integration surface? — If you need voice, image generation, and tool use under one roof today, GPT's ecosystem is ahead. If you're building on top of structured data and document intelligence, Claude's context management wins.
None of these are absolute — and in complex enterprise builds, the answer is often a hybrid architecture where GPT handles consumer-facing interactions and Claude anchors the internal reasoning and compliance layer.
What the Real-World Deployment Data Is Telling Us
Benchmarks are a starting point, not a verdict. The more instructive signal comes from watching where enterprises actually allocate their AI budget once the proof-of-concept phase ends and production deployment begins.
Across industries, a clear pattern has emerged in 2025–2026. Enterprises in financial services, insurance, and healthcare are consistently directing their core workflow automation budget toward Claude — particularly for document-heavy processes like policy interpretation, claims summarisation, and regulatory filing support. The reasoning isn't emotional. It's operational. These teams need outputs they can log, audit, and defend. Claude's constitutional design makes that architecture significantly easier to build and maintain.
In contrast, SaaS companies building end-user features — AI writing assistants, customer support copilots, onboarding flows, and search interfaces — are overwhelmingly staying in the GPT ecosystem. The speed of iteration, the mature fine-tuning options, and the sheer weight of community knowledge around GPT-based systems mean that SaaS product teams can move faster with lower overhead.
What's most telling is what happens at Series B and beyond, when companies that started on GPT for speed begin evaluating whether their infrastructure can scale with enterprise clients who have procurement requirements around data governance and model explainability. That's the inflection point where model re-evaluation happens — and it's almost always Claude that enters the picture at that stage, often anchoring the internal reasoning layer while GPT continues to handle the consumer-facing surface.
The data point that should make every product leader pause: the average cost of re-platforming from one foundation model to another — once prompt libraries, fine-tuning pipelines, evaluation suites, and integration logic are all in place — is measured in months of engineering time, not days. Choosing the right model for the right use case at the architecture stage isn't a philosophical exercise. It's a financial one.
The 2026 Verdict: Two Winners, Two Different Rings
The AI discourse tends toward horse-race framing — who's winning, who's falling behind, which model is "best." That framing is genuinely unhelpful for anyone actually deploying AI solutions at scale.
The more honest picture is this: Anthropic has built the most capable business-ready AI systems for regulated, high-stakes, enterprise-grade deployment. OpenAI has built the most capable consumer and developer platform on the planet. Both are tier-one. Both are winning. In different rooms.
The strategic question for any AI development company or enterprise product team is simply: which room are you building for?
At NeuraMonks, our model selection process doesn't start with benchmarks — it starts with risk profile, workflow architecture, and deployment context. Because the difference between a well-placed model and a mismatched one isn't usually visible in the demo. It shows up in production, at 2am, when something goes wrong and you need to know exactly why.
The most sophisticated enterprise teams we've worked with have stopped asking "which model is better" altogether. They've replaced that question with a more useful one: "which model is better for this specific layer, with this specific risk profile, serving this specific user type?" That reframe changes the entire procurement conversation — from a vendor beauty contest to an engineering decision with defensible logic behind it.
If you're a founder or CTO who hasn't yet stress-tested your model selection against your actual production failure modes, that's the conversation worth having before the architecture hardens and the cost of changing direction becomes a number that requires a board-level discussion.
The specialisation era isn't a complication — it's leverage. Two world-class models, two distinct strengths, both accessible via API today. The tier list is settled. The only open question is where your product actually lives in it — and whether the team building it has been honest enough with themselves to place it correctly.
Not sure which model belongs in your stack?
Every architecture decision has a risk profile behind it. At NeuraMonks, we map your workflow, your failure modes, and your compliance requirements to the right model — before a single line of production code is written.
If your team is at the point of committing to an AI architecture and wants a second opinion from people who've built these systems across fintech, healthcare, and enterprise SaaS — let's talk.

Ketan Kanjiya
Ketan Kanjiya is a Machine Learning researcher and Chief Research Officer at Neuramonks, an AI-focused technology company based in Ahmedabad, Gujarat. With hands-on expertise in AI/ML, image processing, and web application development, he has led research initiatives across F(x) Data Labs and Kshatrainfotech. Ketan writes to simplify advanced technical concepts for developers and tech enthusiasts alike.